My answers to the questions: please point out if I am misunderstood anything
- Why is the second derivative much more expensive to compute than the first derivative?
Because instead of following the original computation graph, we need to construct a new one that corresponds to the calculation of first-order gradient?
- After running the function for backpropagation, immediately run it again and see what happens.
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time.
- In the control flow example where we calculate the derivative of
dwith respect toa, what would happen if we changed the variableato a random vector or matrix. At this point, the result of the calculationf(a)is no longer a scalar. What happens to the result? How do we analyze this?
Directly changing would give the “blah blah … only scalar output” which is what 2.5.2 is talking about. I changed the code to
a = torch.randn(size=(3,), requires_grad=True)
d = f(a)
d.sum().backward()
and a.grad == d / a still gives true. This is because in the function, there is no cross-element operation. So each element of the vector is independent and doesn’t affect other element’s differentiation.
- Redesign an example of finding the gradient of the control flow. Run and analyze the result.
SKIP
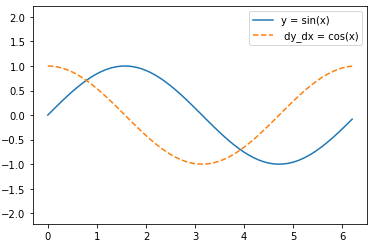
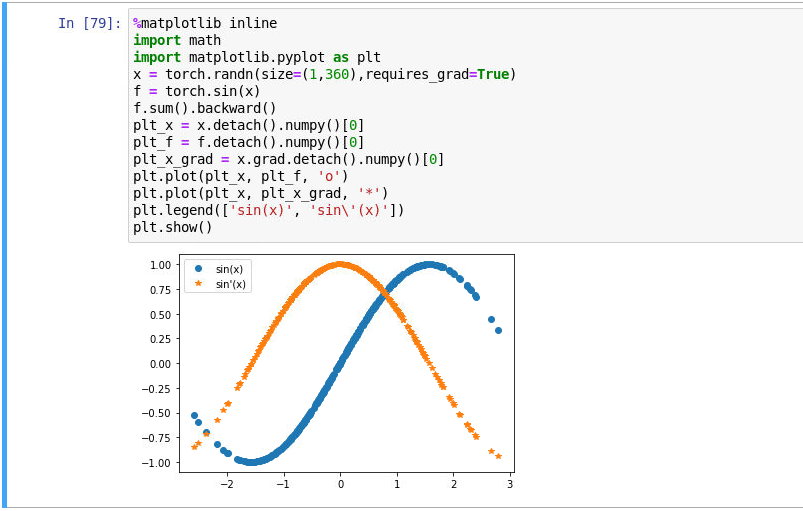
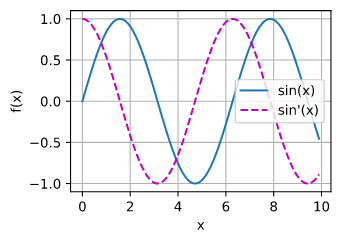
- Let $f(x) = \sin(x)$. Plot $f(x)$ and $\frac{df(x)}{dx}$, where the latter is computed without exploiting that $f’(x) = \cos(x)$.
import numpy as np
from d2l import torch as d2l
x = np.linspace(- np.pi,np.pi,100)
x = torch.tensor(x, requires_grad=True)
y = torch.sin(x)
y.sum().backward()
d2l.plot(x.detach(),(y.detach(),x.grad),legend = (('sin(x)',"grad w.s.t x")))