Then I found
It didn’t show when I switched to tab "pytorch"at first.
@anirudh So does
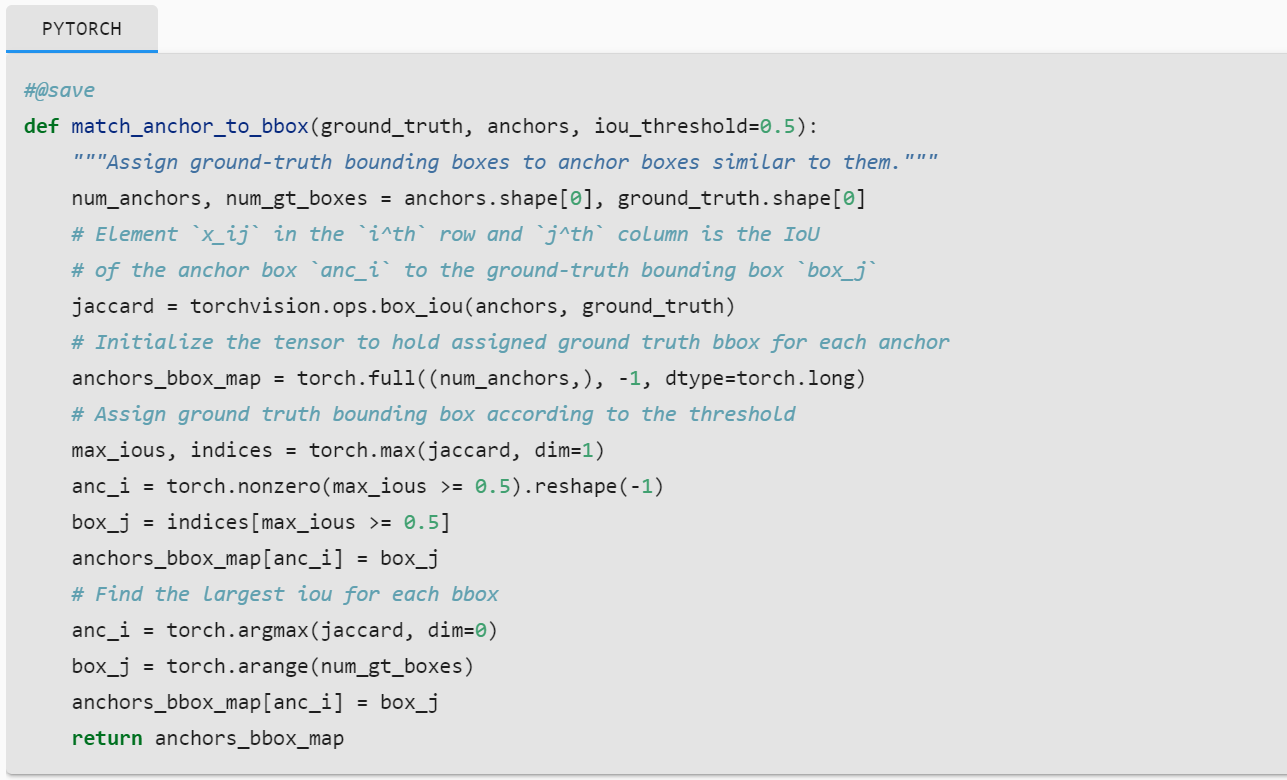
match_anchor_to_bbox.So does
offset_inverse and multibox_detection.@anirudh
Is there some way to fix these?
This is a known issue. The tab rendering is managed by d2lbook.
match_anchor_to_bbox doesn’t faithfully implement the algorithm presented in the text.
# Find the largest iou for each bbox
anc_i = torch.argmax(jaccard, dim=0)
box_j = torch.arange(num_gt_boxes, device=device)
anchors_bbox_map[anc_i] = box_j
In particular, there might be cases where anc_i is the max of multiple columns (j). The code above will assign the last j to anc_i. It should be noted that the code is a simplification of the algorithm.
Hi @gcy, can you please elaborate the same? Also, feel free to open a PR to fix something that might be wrong! 
@anirudh Using the algorithm, we will have the result in the left image, whereas the code gives the right. The table has the same layout as in Fig. 13.4.2.

Thanks @gcy for raising this issue. I think it should be fixed with the following change. Let me know what do you think about the same. I’ll then make a PR.
#@save
def match_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""Assign ground-truth bounding boxes to anchor boxes similar to them."""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# Element `x_ij` in the `i^th` row and `j^th` column is the IoU
# of the anchor box `anc_i` to the ground-truth bounding box `box_j`
jaccard = box_iou(anchors, ground_truth)
# Initialize the tensor to hold assigned ground truth bbox for each anchor
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# Assign ground truth bounding box according to the threshold
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= 0.5).reshape(-1)
box_j = indices[max_ious >= 0.5]
anchors_bbox_map[anc_i] = box_j
# Find the largest iou for each bbox
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
gt_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = gt_idx
jaccard[:, gt_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
Yes, exactly! I would suggest changing gt_idx to something like box_idx to make the naming more consistent.
Why do we discard the columns from the box intersections if all we’re returning are the mappings fo the anchors to GT labels? Is it unnecessary code?
In function multibox_target, we assign categories to every anchor and the index of negative class is 0. So the category indices of positive class starts from 1.
class_labels[indices_true] = label[bb_idx, 0].long() + 1
The above sentence in multibox_target add 1 to original category indices. (Which means in our original dataset we should label ground truth bboxes starting from 0 not 1.)
However, in the function multibox_detection when we are predicting, we are indexing negative class to -1 as following:
class_id[below_min_idx] = -1
Actually it kind of confuses people.
Good question. I think it is because our first goal is to make sure all ground-truth bboxes were assigned to anchors.
Think about it, if we don’t discard the columns, we might not be able to assign one ground-truth bbox to any anchor. This is possible, and if this happen, there would be no candidate predicted bbox for that ground-truth bbox, which means we wasted a ground-truth label.
In assign_anchor_to_bbox the threshold argument is not used in the body of function. I think the 0.5 in the body should be replaced by the iou_threshold?
Could someone please help me understand the following block of code?
# Generate all center points for the anchor boxes
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
What is the role of steps_h and steps_w?
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # Handle rectangular inputs
what does the Annotation “#Handle rectangular inputs” mean?
They are used to normalize center_h,w from 0 - 1
I think this is a typo.
There should be no * in_height / in_width.
This is justified by
thus, the range is between 0 and 1.
If in_height is larger than in_width, the claim of $[0,1]$ might not hold. This fact is demonstrated by switching h and w of the shown image, and printing out boxes[250, 250, :, :], of which one value is 1.13, i.e., strictly greater than 1.
Hi
can someone enlighten me about the concept of offsets ( offset label or offset prediction )?
Actually, the factor * in_height / in_width has the following effect:
For scale s and ratio r, the corresponding anchor box has w=s * \sqrt(r) * in_height and
h=s / \sqrt(r) * in_height
That’s why the aspect ratio now is indeed r, as you can observe from the figures
Going by the text in section 14.4.1, Can someone please explain how width and height of the anchor box was determined to be w x s x sqrt(r) and h x s / sqrt(r)? If this were true, then the aspect ratio of the anchor box would be (w / h) x r which seems contradictory. Thanks!
So from what I understand, this algorithm makes sure to return anchors not more than the ground truth boxes. Do I understand it right?