Nit: There is a small typo: “diagramtically” -> “diagrammatically”
Should the equation (4.1.5) be H_1 = \sigma(X W_1 + b_1) to match the definition of the weight and input matrices defined in Section 3.4.1.3?
Hi @Andreas_Terzis, sharp eyes! Fixed here https://github.com/d2l-ai/d2l-en/pull/1050/files
As for your second question, sorry for the inconsistency. They both work, but the matrixes are in “Transposed” form. To be specific:
-
In equation (4.1.5), we have \mathbf{W}_1, in a dimension of (q , d); and $\mathbf{X}$ in a dimension of (d, n).
-
On the other hand, in equation of section 3.4.1.3, we have \mathbf{W}, in a dimension of (d, q); and $\mathbf{X}$ in a dimension of (n, d).
Let me know that is clear enough.
Thanks for the quick reply and for clarifying the differences in matrix dimensions
You can consider whether you want to explicitly mention the dimensions of \mathbf{W}_1 and \mathbf{X} in 4.1.5 to avoid confusion with the previous definitions. Doing so would also help with readers that do go through the book sequentially.
Best
What would be the explanation for the last question? As far as I can tell, it makes little difference if we apply the activation function row-wise (which I’m guessing refers to applying the activation function to each instance of the batch one by one) or apply the function to the whole batch. Won’t both ways yield a similar result?
Hi @Kushagra_Chaturvedy, minibatch may not be as representative as the whole batch. As a result, parameters learned from the (small) minibatch dataset may get some weird gradients and make the model harder to converge.
Got it. But isn’t the question talking about activation functions? How will applying the activation function row-wise or batch-wise affect the learning? Also if we keep on applying the activation function row-wise for batch_size number of rows, won’t it give the same result as applying the activation function batch-wise for a single batch?
hey @Kushagra_Chaturvedy, from my understanding, the last question in the exercise was asking what if the minibatch size is 1?. In this case, the minibatch is too small to converge.
How do we explain 2nd question?
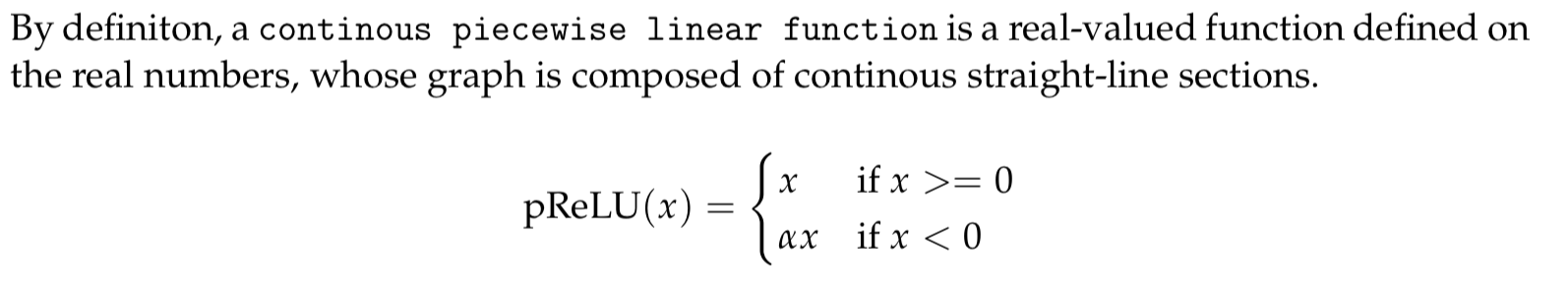
In 4.1.1.3,
For a one-hidden-layer MLP whose hidden layer has h hidden units, denote by H∈Rn×h the outputs of the hidden layer, which are hidden representations
What is the sentence trying to say?
Hi @tinkuge, we define hidden representations or hidden layer in this sentence. (As a lot of deep learning concepts are referred to the same thing.  )
)
How do you write a pRelu function from scratch which can be recorded. I wrote the following
def prelu2(x,a=0.01):
b = np.linspace(0,0,num=x.size)
for i in np.arange(x.size):
if(x[i] < 0):
b[i]=a*x[i]
else:
b[i]=x[i]
return b
But it doesn’t work and gives the error that inplace operations are not permitted when recording.
Thanks. So PReLU is defined in mxnet.gluon.nn.activations. So how does one use it?
Hi @asadalam, are you asking about API or the fundamental technique? If the latter, I recommend you to read the paper, it will provide rigorous math logic. If you are asking the former, first you define prelu = nn.PReLU(), then you apply this prelu to your network. Check more at the API.
don’t understand the last question in the exercise. how could the activate function be applied to the minibatch? suppose we have 256 samples, how is this implemented and what would be the outcome? Thanks!
I have been watching many video tutorials and some books.As far as i saw this is the best But having understood the mathemathical part ,i have a problem of memorizing the programming part and also writing it by my self both with frameworks or from scratch. any help on that please…