https://zh-v2.d2l.ai/chapter_computer-vision/image-augmentation.html
若出现报错certificate verify failed: certificate has expired,在代码前添加
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
即可解决
原文出处:https://blog.csdn.net/weixin_41870042/article/details/120752564
3 Likes
为什么反向传播是用 l.sum().backward(),而第三章3.6用的是 l.mean().backward(),损失函数都是 nn.CrossEntropyLoss()啊
这里的损失函数用的也是交叉熵损失吧 sum和mean在backward的时候应该不会影响到最终结果吧
需要科学上网吧。。。。。。。。。。。。。。。
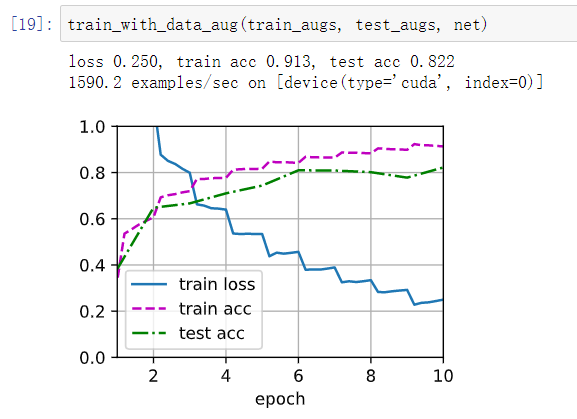
使用图像增广的结果:loss 0.181, train acc 0.937, test acc 0.835
不使用图像增广的结果:loss 0.086, train acc 0.971, test acc 0.824
对比可以看出,使用图像增广时,train acc更小,而 test acc更大,train loss 更小,这说明图像增广减轻了过拟合
1 Like
请问老哥搞清楚为什么了吗,我同样有此疑问
问题1.d2l 没有image包 ,解决方法:在当前文件from PIL import Image , 将d2l.image.open()换成image.open()。
问题2. AssertionError :‘detach ’。 PIL的image类 没有detach属性。traceback定位到image.show里面用ax.imshow(d2l.numpy(img)) ,numpy用lamba表达式调用了detach方法。解决方法:自己把image.show源代码复制到当前文件,去掉d2l.numpy() ,把d2l.show_images改成show_images。
问题3.AttributeError: module ‘d2l.torch’ has no attribute ‘resnet18’。解决方法:把d2l.resnet18(10, 3)改成torchvision.models.resnet18(10, 3)。
2 Likes
把亮度色调那些变换都开,设置为0.5,测试精度直接增加了1个多点
1 Like
感谢分享!我也遇到了这个问题,多亏你的方案解决了!
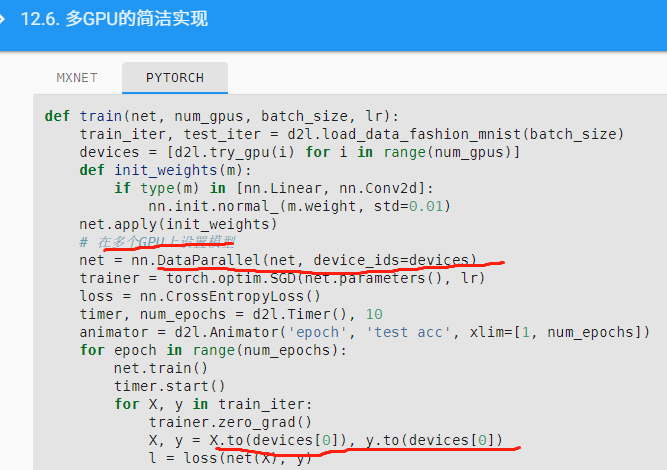
不加这个转移步骤会报错吧,需要手动把模型转移到GPU上,不然是在CPU上
好人一身平安,好人一身平安,好人一身平安,
先移去GPU0作為主来源, 後続的訓練nn.DataParallel会自動分配去其他GPU.
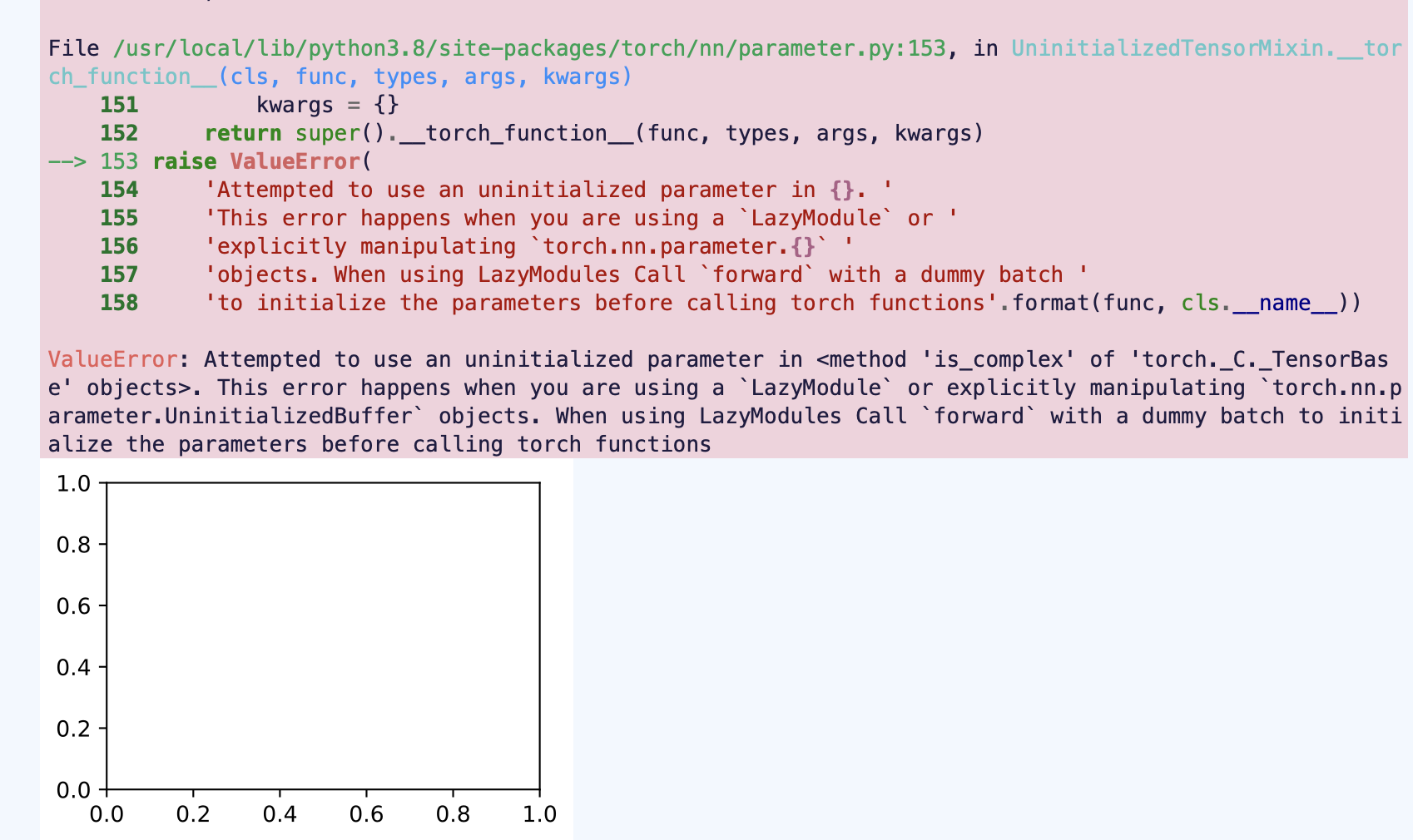
出现这个问题的原因,是d2l包中实现resnet18模型时使用了Lazy层(nn.LazyConv2d, nn.LazyBatchNorm2d),而Lazy层的参数不是静态定义的,而是根据模型第一次执行前向传播时输入的小批量数据来动态确定。对于使用数据并行来进行GPU训练的情形,如果在执行net = nn.DataParallel(net, device_ids=devices)时,模型中Lazy层的参数量仍未确定,则模型从主GPU复制到其它GPU后,Lazy层参数仍处于未确定状态,且主GPU第一次执行前向传播时,只会动态确定主GPU上的Lazy层参数数量,不会同步更新其它GPU上复制的模型中Lazy层的参数数量,从而导致其它GPU上的模型执行前向传播时出错。
解决这个问题的方法,是在执行net = nn.DataParallel(net, device_ids=devices)之前(即模型从主GPU复制到其它GPU之前),先在主GPU上手动调用一次模型的前向传播函数,令模型Lazy层参数确定,之后再执行net = nn.DataParallel(net, device_ids=devices),完成模型在多个GPU上的复制。这样就没有问题了。
具体来说,找到本章代码中的下面这一行:
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
把上面这行代码改为以下三行代码,即可正确运行。
batch_size, devices = 256, d2l.try_all_gpus()
net = d2l.resnet18(10, 3).to(devices[0])
net.forward(torch.randn((1, 3, 32, 32)).to(devices[0]))
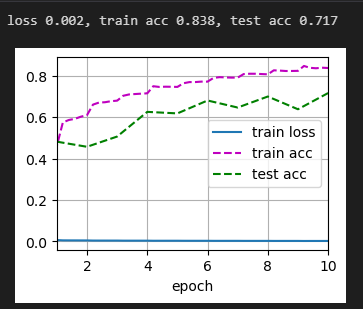
请问为什么我的损失会这么小,是什么问题呢
你看看你的 X = [x.to(devices[0]) for x in X] 这句话是不是写成 X = [x.to(devices) for x in X] 了
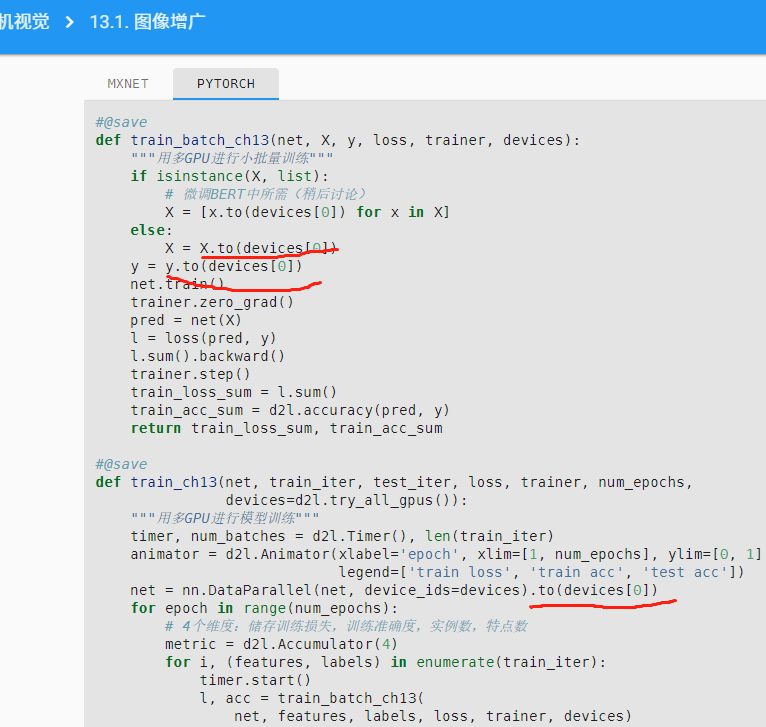
def train_batch_ch13(net, X, y, loss, trainer, devices):
# 如果是个列表就要一个个放到device[0]中
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
其实我在想,如果参数初始化不一致的话这个现象不能证明减轻了过拟合,可能是运气