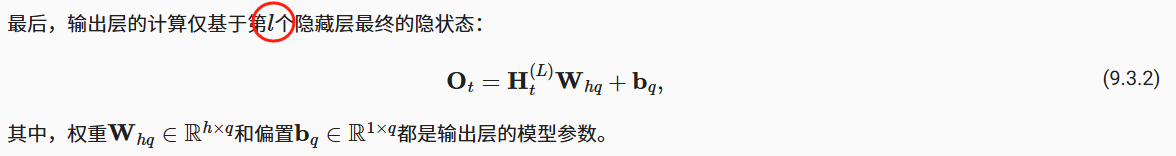“最后,输出层的计算仅基于第l个隐藏层最终的隐状态”
应该是L不是l
9.3.2第二段,
“因为我们有不同的词元,所以输入和输出都选择相同数量”
好像应该是
“因为我们有相同的词元,所以输入和输出都选择相同数量”
我从零开始实现深层循环神经网络,模型如下,不知为何效果不好
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q, W_xh1, W_hh1, b_h1 = params
H, = state
H1, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
H1 = torch.tanh((H @ W_xh1) + (H1 @ W_hh1) + b_h1)
Y = H1 @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim = 0),(H,)gru得同时返回H和H1的state
def get_params(vocab_size, num_hiddens, device):
V=vocab_size
H=num_hiddens
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
def three():
return normal((V,H)),normal((H,H)),torch.zeros(H,device=device)
W_xz, W_hz, b_z=three()
W_xr, W_hr, b_r=three()
W_xh, W_hh, b_h=three()
W_hh1, W_hh2, b_h1=normal((H,H)),normal((H,H)),torch.zeros(H,device=device)
W_hq, b_q=normal((H,V)),torch.zeros(V,device=device)
params=[W_xz, W_hz, b_z,W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q, W_hh1, W_hh2, b_h1]
for param in params:
param.requires_grad_(True)
return params
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q, W_hh1, W_hh2, b_h1 = params
H,H1 = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
H1 = torch.tanh((H @ W_hh1) + (H1 @ W_hh2) + b_h1)
Y = H1 @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim = 0),(H,H1)
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size,num_hiddens),device=device),
torch.zeros((batch_size,num_hiddens),device=device))
H, = state
H1, = state
H和H1一个应该来自上一层,一个来自左端,但是从这个代码来看的话H和H1却是相同的,并且在Z、R、H_tilda中也只用到了H,而没有用到H1,所以这个代码实现的网络应该不是深层循环网络
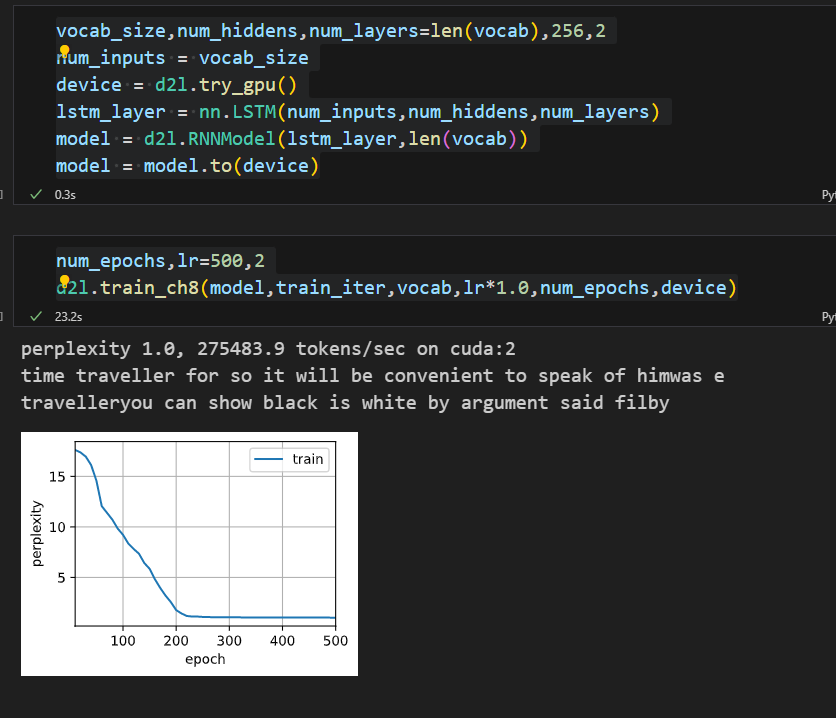
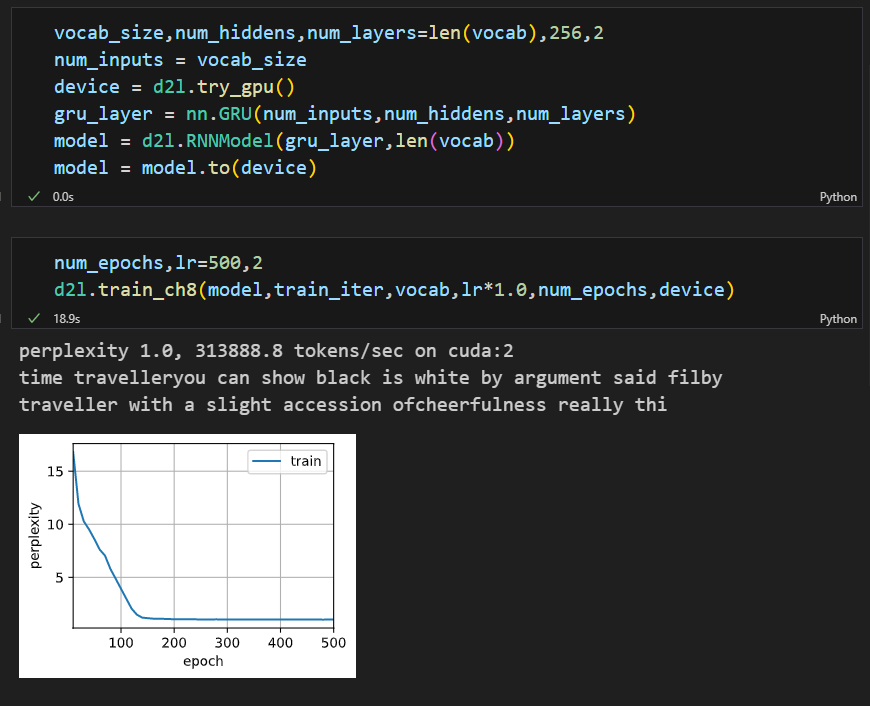
隐藏层单元数量为什么要一致呢?从公式来看可以不一致,入第一层256,第二层128,不知道什么原因,pytorch官方文档上hidden_size 也是数值类型,希望懂得大佬解释下哈。
question1:
def get_deeprnn_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three_layer1():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
def three_layer2():
return (normal((num_hiddens, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xh1, W_hh1, b_h1 = three_layer1() # first layer
W_xh2, W_hh2, b_h2 = three_layer2() # second layer
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh1, W_hh1, b_h1, W_xh2, W_hh2, b_h2, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_deeprnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), torch.zeros((batch_size, num_hiddens), device=device))
def deeprnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh1, W_hh1, b_h1, W_xh2, W_hh2, b_h2, W_hq, b_q = params
(H1, H2) = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
H1 = torch.tanh(torch.mm(X, W_xh1) + torch.mm(H1, W_hh1) + b_h1)
H2 = torch.tanh(torch.mm(H1, W_xh2) + torch.mm(H2, W_hh2) + b_h2)
Y = torch.mm(H2, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H1, H2)
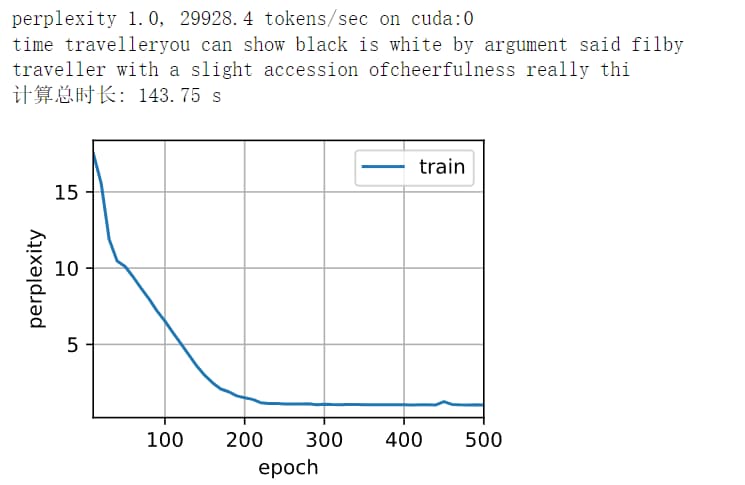
那你第一层的剩下128个打算怎么处理?是直接忽略不用,用第二层128作为输出层输入?还是打算用他与第二层的128连接起来一起作为输出层输出?前者你定义第一层256多余了,后者我觉着应该可以试试