https://zh.d2l.ai/chapter_multilayer-perceptrons/mlp-scratch.html

你应该使用torch.max而不是max
函数原型:
torch.max(input, other, out=None) → Tensor
参数:
input (Tensor) – 输入张量
other (Tensor) – 输出张量
out (Tensor, optional) – 结果张量
例子:
a = torch.randn(4)
a
1.3869
0.3912
-0.8634
-0.5468
[torch.FloatTensor of size 4]
b = torch.randn(4)
b
1.0067
-0.8010
0.6258
0.3627
[torch.FloatTensor of size 4]
torch.max(a, b)
1.3869
0.3912
0.6258
0.3627
[torch.FloatTensor of size 4]
3 Likes
RuntimeError: DataLoader worker (pid(s) 20584, 44860) exited unexpectedly
在运行训练代码时出现这个报错,网上说要把n_workers设置为0,
回到 图像分类数据库那里,把load_data_fashion_mnist返回值里面的n_workers设置为0并重新运行 仍然报错
请教下前辈们这个问题该如何解决
1 Like
问题已经解决了 我重启了notebook 核心原因可能是内存方面的原因(还是不太懂)
另一方面 n_workers 在3.5一节中改变并运行 能否将修改应用到这里 仍然不清楚
如果遇到同样问题的人可以尝试重启重新运行解决问题 如果有大神能帮忙解决上述两个问题我非常感激
我是在加载完后把进程设置为0就可以了,不知道你是不是做了这个操作。
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
test_iter.num_workers = 0
train_iter.num_workers = 0
2 Likes
Original: one hidden, num=256, epoch=10, lr=0.1
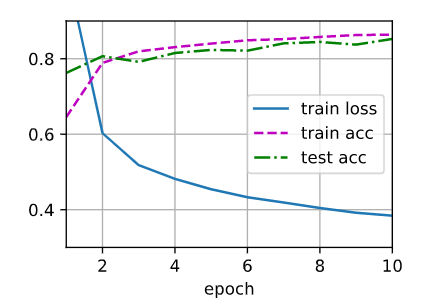
Test1) Change num_hiddens=512
似乎测试集准确率有较大波动
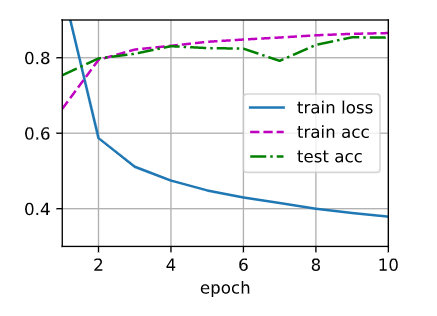
Test2) Change epoch=20
损失函数没有变化,测试集准确率最后没有跟训练集一致
Test3) Change lr=0.05
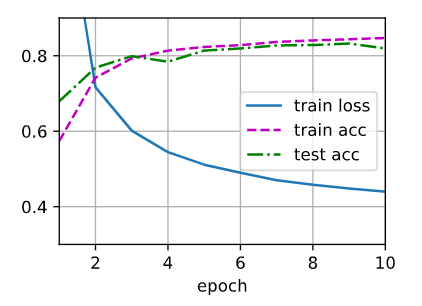
损失函数一直没有达到之前的结果,测试集准确率最后低于训练集
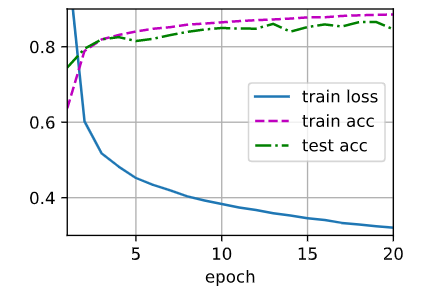
Test4) Adding second hidden layer num=64
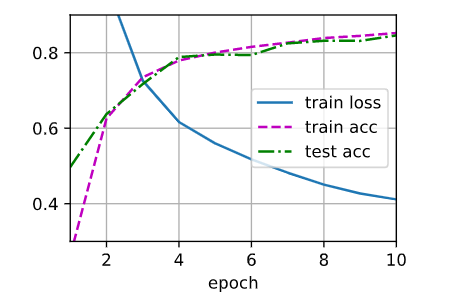
损失函数收敛较慢,开始训练集和测试集准确率较低,但是最后更好接近
Test5) Adding third hidden layer
无论如何修改hiddenlayer num, 都有溢出
1 Like
W1=nn.Parameter(torch.randn(num_inputs,num_hiddens_1,requires_grad=True)*0.01)
请问上面为什么要有*0.01?这个参数的意义是什么?如何确定取值的?
4 Likes
关于问题5请大家指教:我的想法是如果调单一超参数的情况下复杂度是N,那么联合m个超参的复杂度就是N**m。
但是好像部分超参数会有关联,比如batchsize和lr,在降低batchsize的同时提高lr。会得到不错的效果。
关于问题6很希望得到大家的建议,目前我想到的办法是:在调整某个超参的时候,保证别的参数不变,当得到较优数值后再迭代的调别的参数。这样复杂度就是N*M,但是有个疑问,不能保证最后得到的结果是最好的,比如lr在不同batchsize上有不同的最优值。
4 Likes
torch.randn是生成以0为均值1为方差的随机数,之前章节中取的参数的方差是0.01,因此这儿也*0.01,不然参数会有些过大,可能会影响训练结果
5 Likes
增加hidden layer以后,需要增加训练次数才能达到更好的精度,请问这是什么原因啊?
我的理解是,你增加了隐藏层,就需要更多次学习来得到其中的权重,否则,你学习不到理想结果的权重。
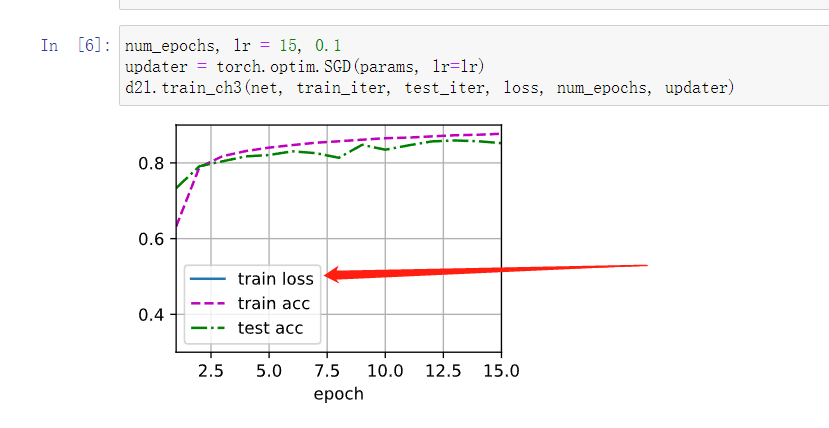
Plus One 我也正想问这个问题 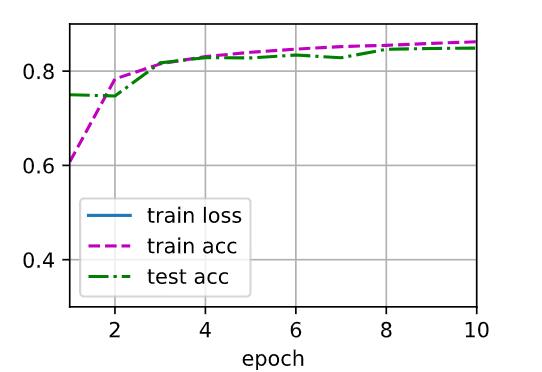
你debug进代码查看loss值,会发现loss的值很小,大概小数点后三(0.001),所以在图形上无法辨认
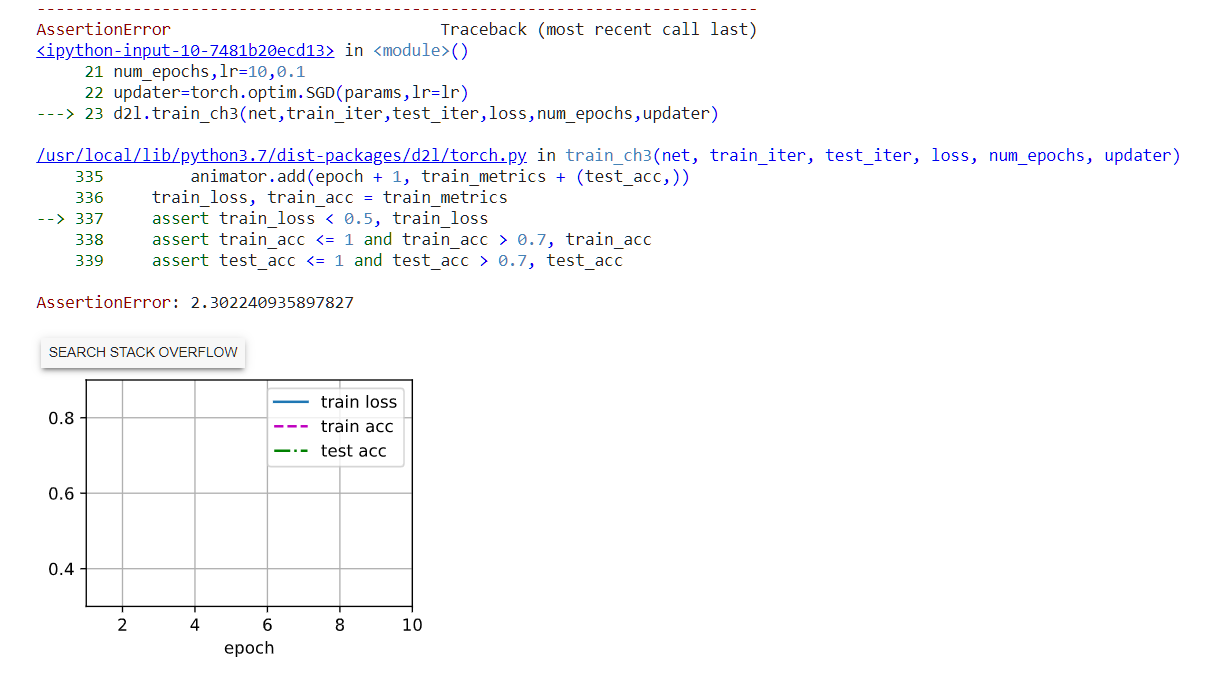
想问下我运行老师的代码时候,就会报类似于您最后的这个错误,请问这是什么原因呢,请教下修改建议
问题解决了,0.17.1的d2l包封装的pytorch的训练模型迭代的代码有一个小问题,train_epoch_ch3函数的第9行代码应该是“l.mean().backward()”,d2l包中的封装代码则是“l.sum().backward()”导致损失越来越大,会发生上述assert问题,目前GitHub上的最新版本的d2l包没有这个问题。
1 Like

请问 我也是会报出最后那个异常 这个是什么意思啊
1 Like
所以应该卸载现在d2l,再重装是吗? 现在更新到0.17.3了可以运行了