def get_net():
net = nn.Sequential(nn.Linear(4, 10), nn.ReLU(), nn.Linear(10, 1))
net.apply(init_weights)
return net
Is it correct to call this Multi-Layer Perceptron an RNN? Or does calling something an RNN only depend on the having a sliding window training & label set?
tau is 4 in this case correct? What do both 10s mean contextually?
A few about the max steps section
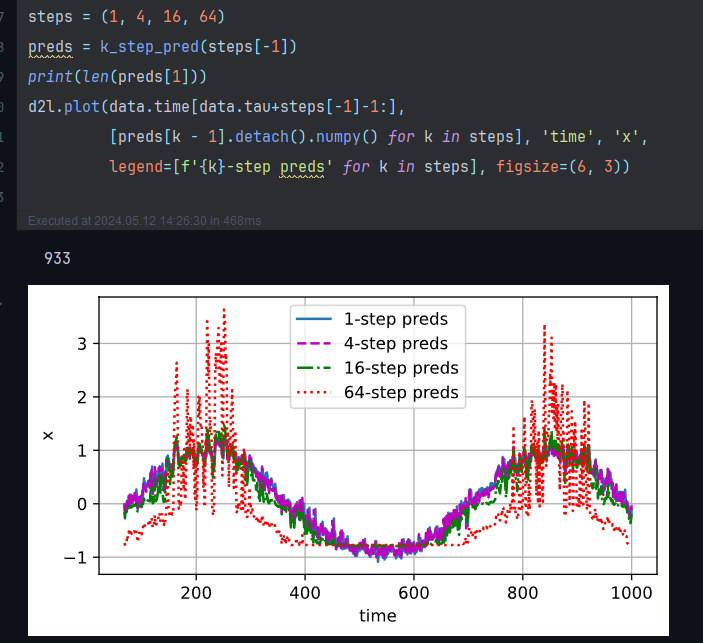
Are you predicting a sequence of length step size, or are you shifting each window by the step size?
I’m confused about this code in Chapter 9.1. If I understand correctly, our FEATURE should be a T-tau fragment of length tua; why is the FEATURE here actually a tau fragment of length T-tau
def get_dataloader(self, train):
features = [self.x[i : self.T-self.tau+i] for i in range(self.tau)]
self.features = torch.stack(features, 1)
self.labels = self.x[self.tau:].reshape((-1, 1))
i = slice(0, self.num_train) if train else slice(self.num_train, None)
return self.get_tensorloader([self.features, self.labels], train, i)
Is this correct? IMO, ‘overestimate’ should be replaced by ‘underestimate’. If we rely on statistics, we are unlikely to meet the infrequent words. So will conclude they have zero or close to zero occurrences. That is why the use of ‘overestimate’ is perplexing.
“This should already give us pause for thought if we want to model words by counting statistics. After all, we will significantly overestimate the frequency of the tail, also known as the infrequent words.”
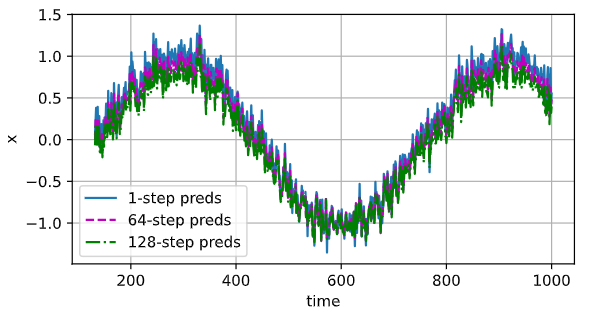
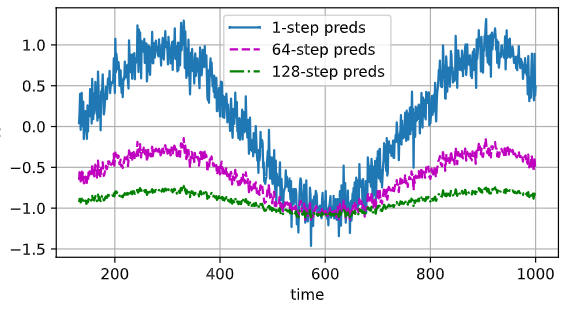
I’m quite amazed but what a bad performance this extra non-linear layer added. Does anyone understand why this is so bad now? (trained for 10 epochs)
"This is all I changed in the net self.net = nn.Sequential(
nn.LazyLinear(10), # Lazy initialization for an input layer with 4 outputs
nn.ReLU(), # Another non-linear activation function
nn.LazyLinear(1) # Output layer producing 1 output
)
"
@d2l.add_to_class(Data)
def insert_kth_pred(self, pred, k):
for i in range(1, k):
self.features = shift(self.features, i, self.tau-i)
self.features = change(self.features, pred, k-1)
for i in range(4):
preds = model(data.features).detach()
data.insert_kth_pred(preds, i+1)
trainer.fit(model, data)