https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html
input is 3 dimensions, why does norm_shape use the last two dimensions of the input in the example ,but the last one in the final trainning. normalized_shape is input.size()[1:], but in the trainning, normalized_shape is input.size()[-1]. what’s the difference? why change?

I used pytorch. May I ask you a question about two different methods? Mxnet’s method is right and wrong in pytorch. The following changes should be made.
1 Like
Can LN be done in a single dim? such as tensor with shape [2,3,4], could the LN be done in norm_shape=shape[1] (3)?
Hi @foreverlms, great question. Yes Layernorm can be done at a single dim, which will be the last dimension. See more details at pytorch documentation: “If a single integer is used, it is treated as a singleton list, and this module will normalize over the last dimension which is expected to be of that specific size.”
Book content is very helpful for those who want to learn Deep learning from scratch however
request you to please add more graphical presentation / images. It will helpful to understand concept easily.
1 Like
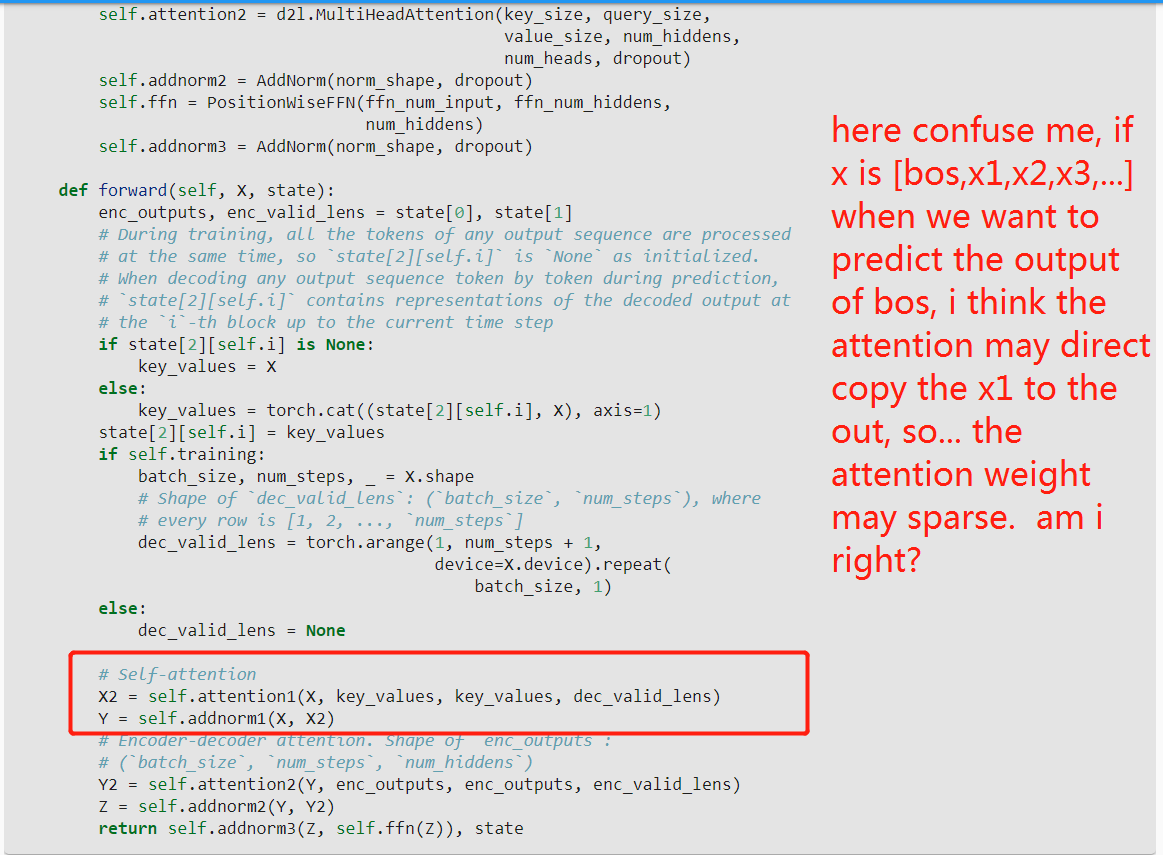
Hi @min_xu, I am not fully understand your question… but in general you can imagine that the attention layer has seen a lot example start with “BOS”. As a result, it will predict “BOS” as the first token.
thank you , i find the code process what i thinking. mask the data after the timesteps when the model is trainning
thank you !
In decoder block there is
self.attention = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout, use_bias)
...
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
According to the paper Attention Is All You Need, the ffn has width [d_model, ?, d_model] where d_model is the embedding size of a token. But in the above code num_hiddens is used as both the embedding size and the embedding size in attention block (the dimensionality of an input after the linear map in multi-head attention). It is not the best way to implement it if I’m correct.
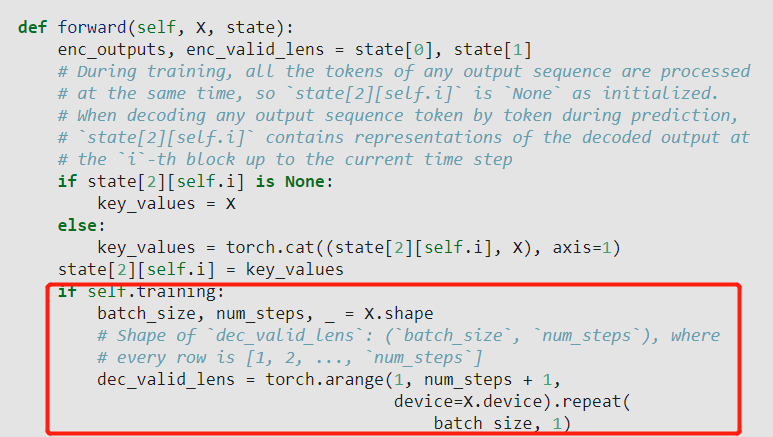
class DecoderBlock
...
def forward(...)
...
if self.training:
...
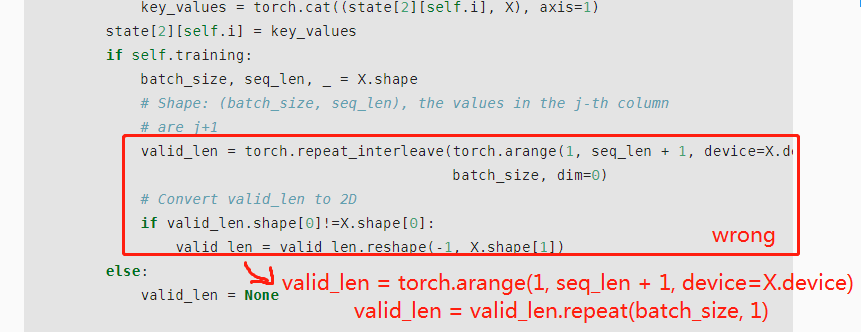
dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
I’m not sure this is true. In both cases (train and inference) decoder self-attention needs two masks: padding and causal (other possible names: look-ahead or auto-regression). For convenience, they are usually combined into one tensor during calculations.
When predicting, target tokens are feed into the Decoder one by one. At this point the num_steps is considered to be 1, that is, each time you enter a tensor of the shape torch.Size([1, 1, num_hiddens]), this will result in the position encoding of each token being the same, i.e., the position encoding fails at prediction
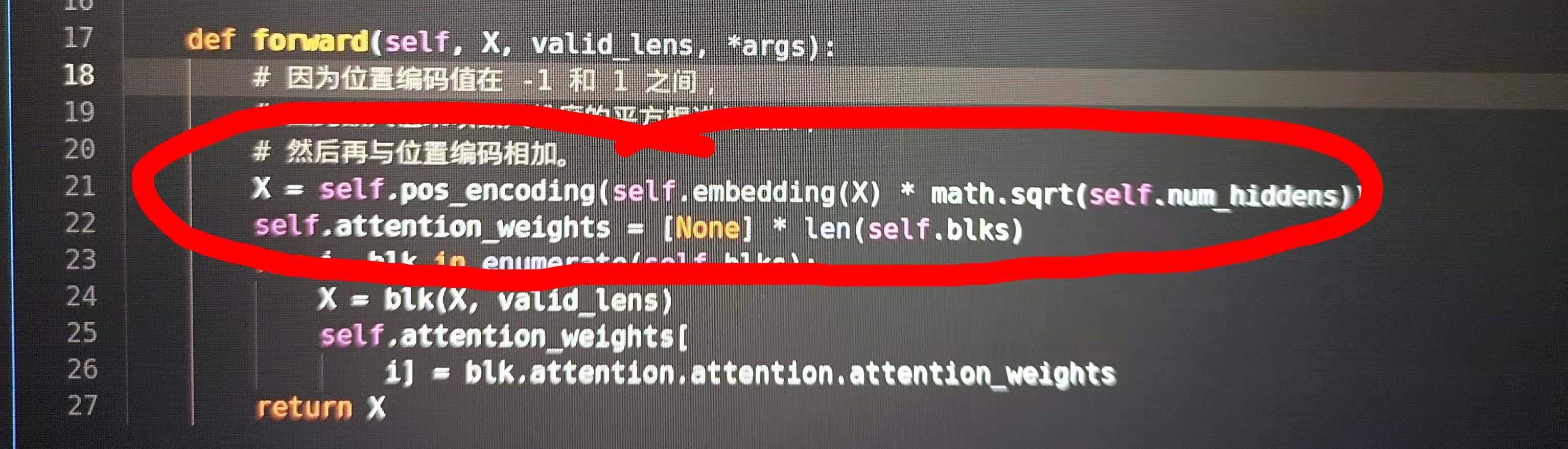
the reason of multiplying each element by sqrt(num_hiddens) is the use of the Xavier_unifom_ to initialize parameters of the Embedding, each element is very small compared to 1/-1. (see the following figure) ,but no Xavier_unifom_ is used here…
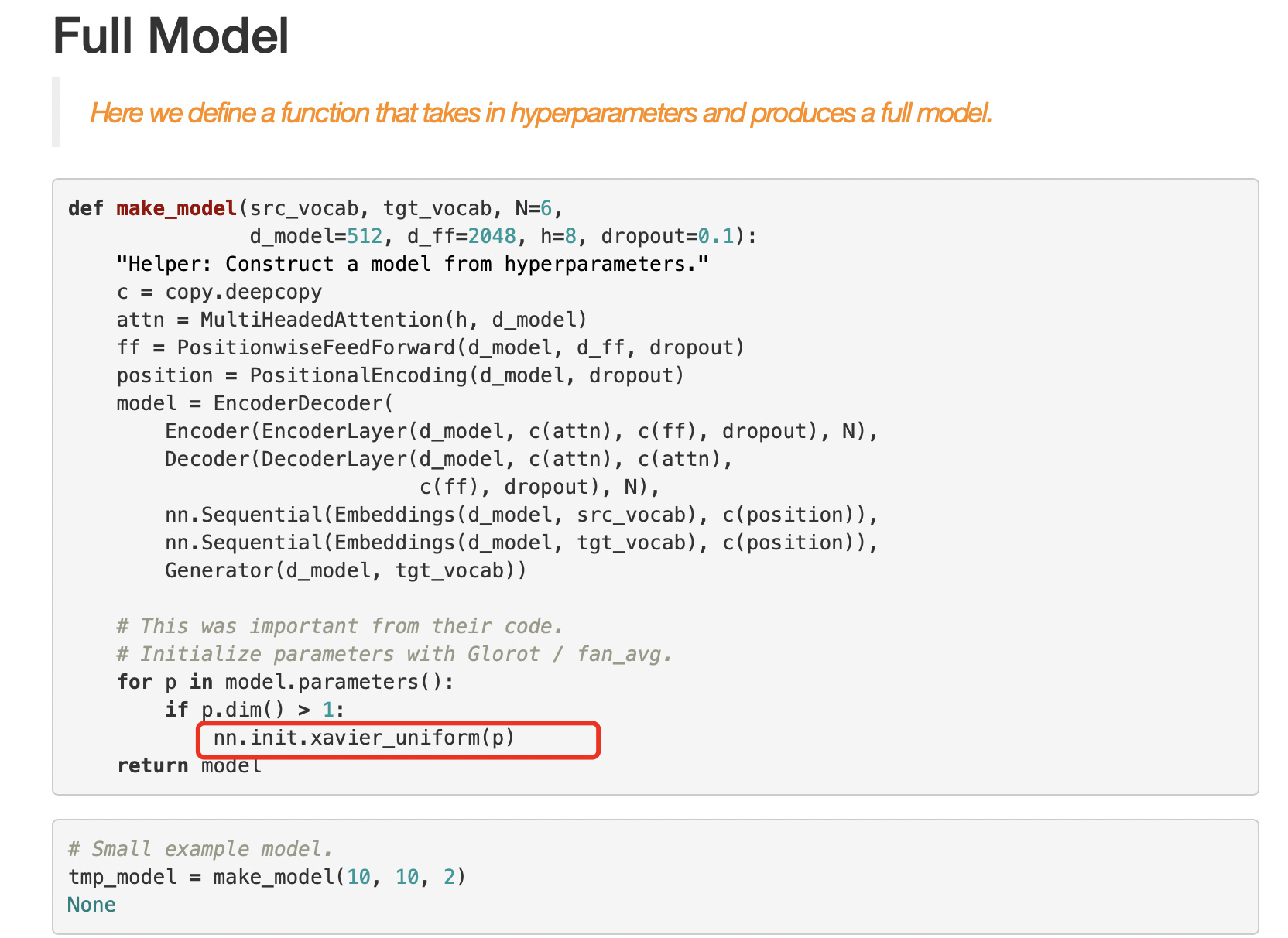
Reference:http://nlp.seas.harvard.edu/2018/04/03/attention.html