I’m having hard time interpreting the last part of the code.
Why do we use 'wrong = preds.type(y.dtype) != y’ instead of ‘wrong = preds != y’, which generate the exact same result.
And why does the first one work? The y.dtype just generates the type of y.
Answer to the funniest question:
Is it always a good idea to return the most likely label? For example, would you do this for medical diagnosis? How would you try to address this?
@d2l.add_to_class(SoftmaxRegression)
def show_top_dimensions(self, X, dims=1, labels=None):
y_hat = self.forward(X)
topk = torch.topk(y_hat, dims)
for i in range(dims):
rank = float(topk[0][0][i])
ind = int(topk[1][0][i])
print(ind, labels([ind]), rank)
print()
g = iter(data.val_dataloader())
X, y = next(g)
cols = 2
for i in range(cols):
model.show_top_dimensions(X[i], 3, data.text_labels)
data.visualize((X, y), ncols=cols)

Regarding the first excercise, this solution works pretty fine.
X_max = X.max(1, keepdim=True).values
X_shift = X - X_max
X_shift_prob = softmax(X_shift)
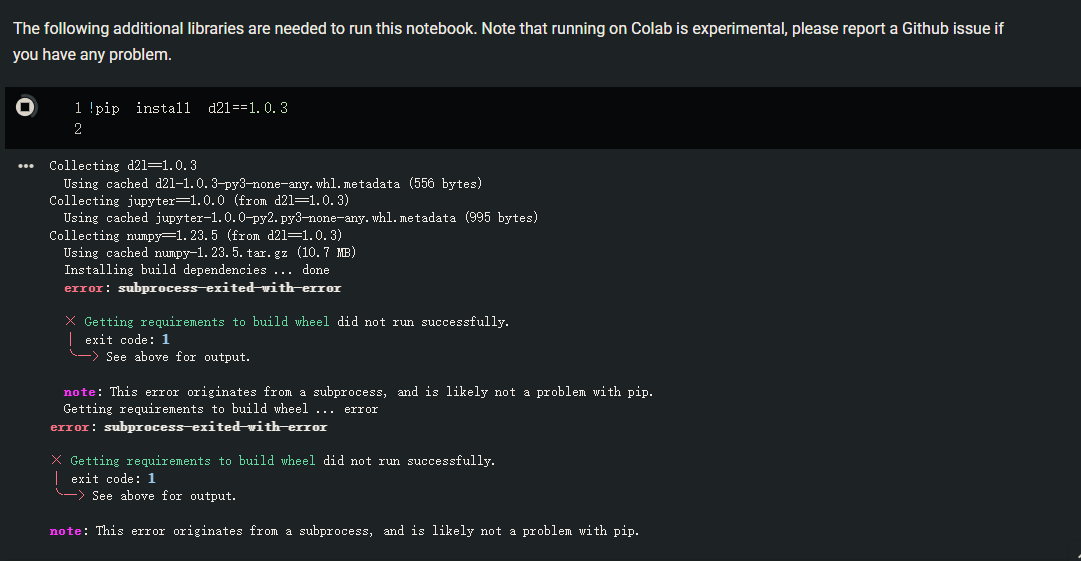
i got issues in installing dependencies in colab, screenshot is attached.