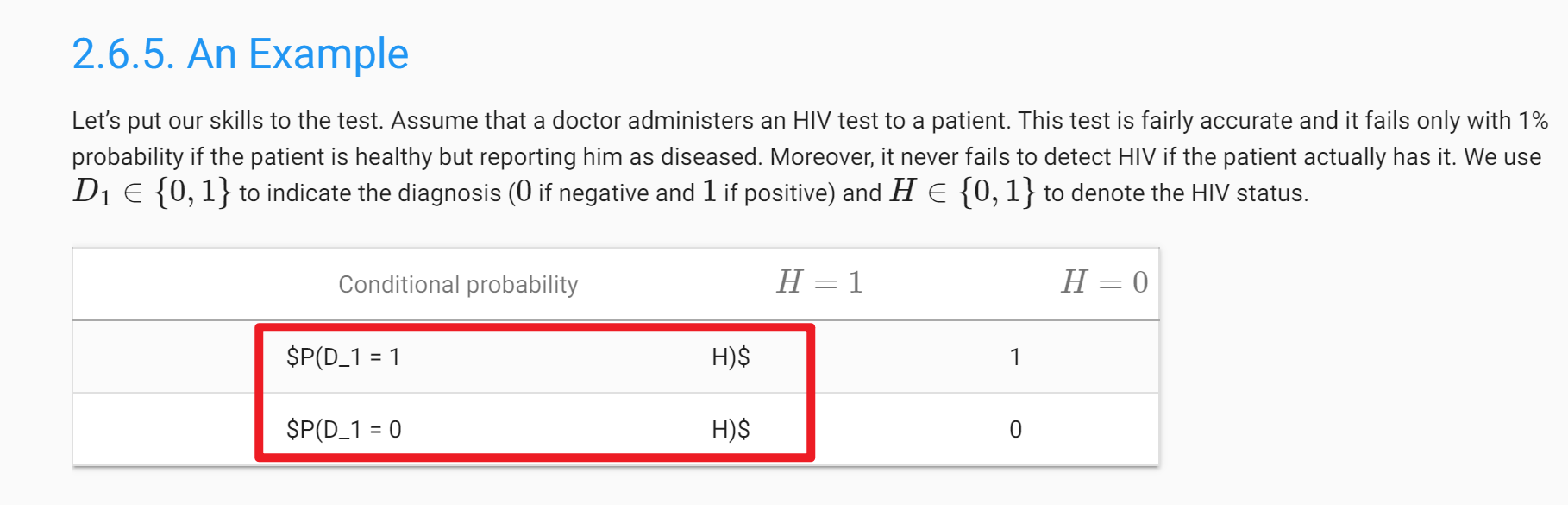
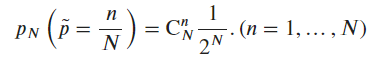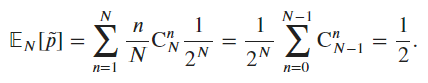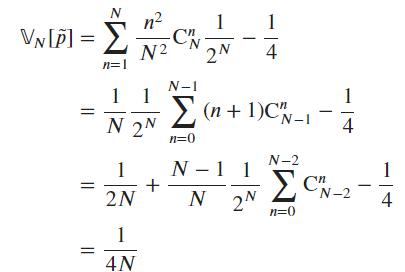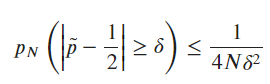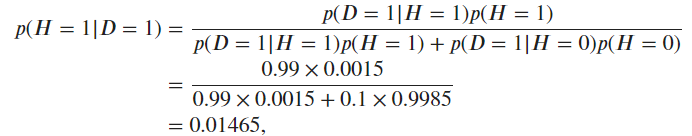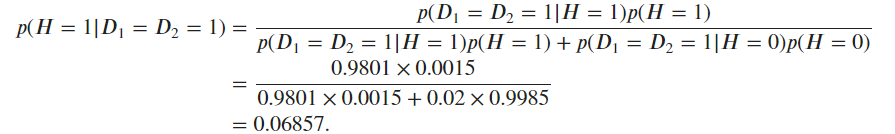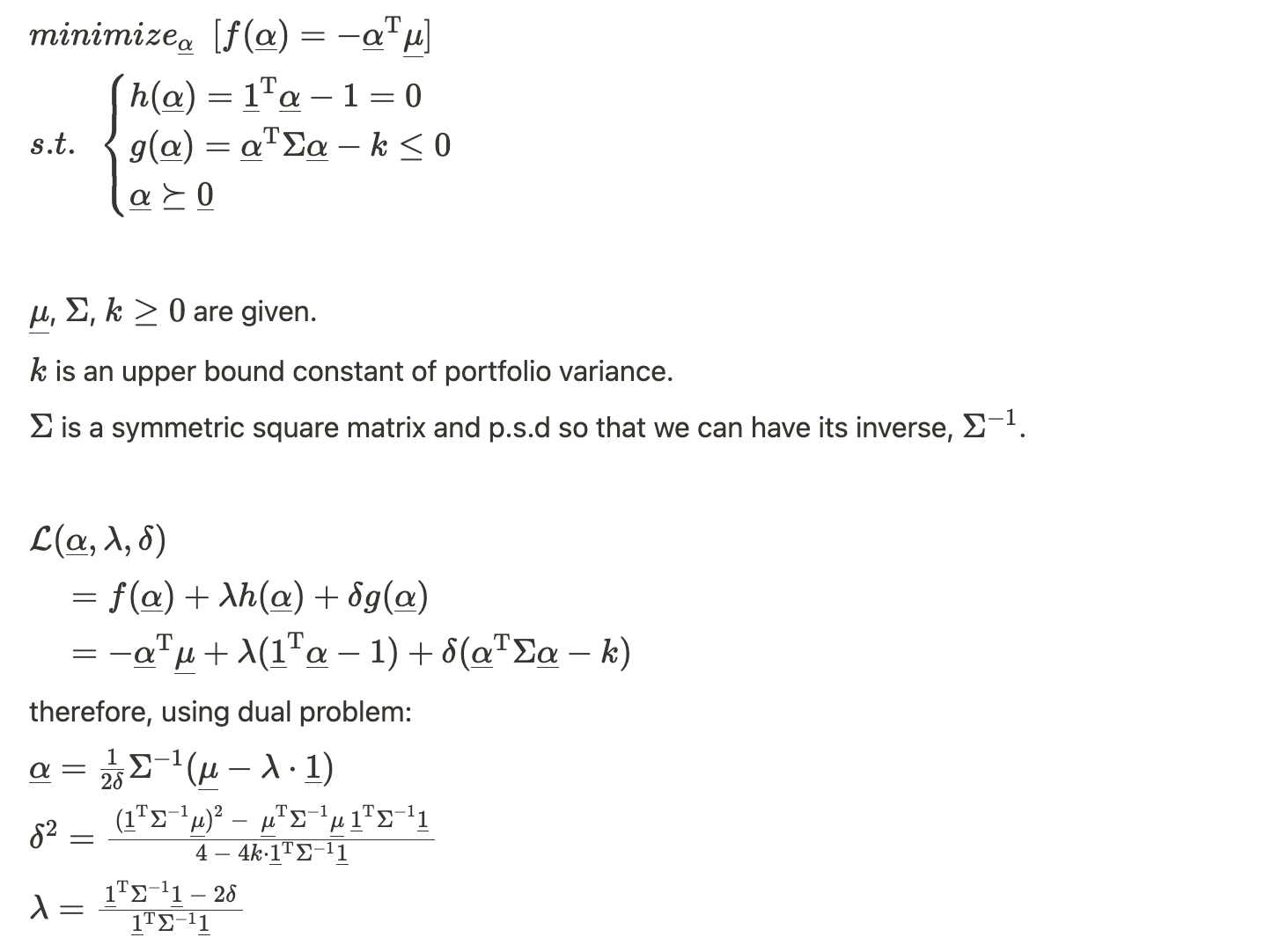For the last question
If we assume the test result is deterministic, then
P(D2=1|D1=1) = 1
P(D2=0|D1=0) = 1
Doing first experiment twice does not add additional information. Therefore, P(H=1|D1=1,D2=1) == P(H=1|D1=1). You can derive the equation by doing some arithmetic.
I don’t understand equation 2.6.3 . On the right side, why wouldn’t P(A) on the top cancel out with P(A) on the bottom, and since the other term on the bottom right which is the sum of all b in B for P(B|A) equals 1, wouldn’t that mean it would then just simplify to P(A|B) = P(B|A) which is obviously incorrect?
Yes, the equation is slightly wrong. The updated equation should sum over all possible ‘a’ values in the sample space(a and its complement so that it gets normalized accurately), Reference
Would have been great and more clear to actually see what numbers you multiplied in the example, for someone never doing stats before, it can be hard to comprehend all the formulas without any explanations.
The same answer. Quite conterintuitive, though. I think it is because the joint FPR 0.02 increased a lot compared to the original example 0.0003. So the positive result can still be confusing to patients.