https://d2l.ai/chapter_linear-regression/linear-regression-scratch.html
The size of the update step is determined by the learning rate
lr. Because our loss is calculated as a sum over the minibatch of examples, we normalize our step size by the batch size (batch_size), so that the magnitude of a typical step size does not depend heavily on our choice of the batch size.
I didn’t get this, can someone explain in simpler words?
I hope my words are simpler  . From my understanding of the passage, in the weight update equation (w:=w - lr * D, where D is the gradient ) after each step of training on a minibatch (let’s say m examples per minibatch) we divide the total minibatch gradient with the size of the minibatch (which is m, so D=minibatch_grad/m) and then multiply by the learning rate, thus the greater effect on our step size towards the minimum is heavily depend on lr rather than m.
. From my understanding of the passage, in the weight update equation (w:=w - lr * D, where D is the gradient ) after each step of training on a minibatch (let’s say m examples per minibatch) we divide the total minibatch gradient with the size of the minibatch (which is m, so D=minibatch_grad/m) and then multiply by the learning rate, thus the greater effect on our step size towards the minimum is heavily depend on lr rather than m.
1 Like
I agree with you, instead of using w:=w - D, which is heavily depends on m, we introduce lr to set the limit for D, which is now less influance of m.
From my understanding, we divide the total loss to batch size in order to get average loss for a given batch. Contrary to total loss, average loss does not depend on the batch size.
While implementing this code, I got an error
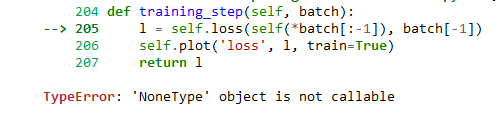
which I realized is might be because of ‘loss’ variable in LinearRegressionScratch class, checked using model.dict.keys(). To get away with this error I defined a new loss function with name ‘loss_’ and changed it in training_step. But in this case my model is not getting trained properly.
Am I missing something here?
Looks like the error was because if keras version. going back to keras=2.15.0 solved it.
I find the method fit_epoch code incredibly difficult to follow. The explanation is sparse and fails to explain much of the meat of the code. It covers the overarching idea of the method but im left clueless as to the actual functionality of some of the called variables… sometimes it feels like variables seem to be called out of nowhere and attempting to find them in the 3.2 documentation turns up no results. Greater documentation like comments within the code itself would go a long way in helping to make the intent of calling certain variables clear.