https://d2l.ai/chapter_recurrent-neural-networks/rnn-scratch.html
so, where is the code which have the function of detaching the gradient
@terrytangyuan, in TF do we need to use https://www.tensorflow.org/guide/advanced_autodiff#stop_gradient ?
Why tensorflow version’s PPL keeps so high and bumpy? even sets lr=0.0001 and uses Adam optimizer?
Something goes wrong?
I have fixed the bug, Just transpose Y accordingly (because we have transposed X):
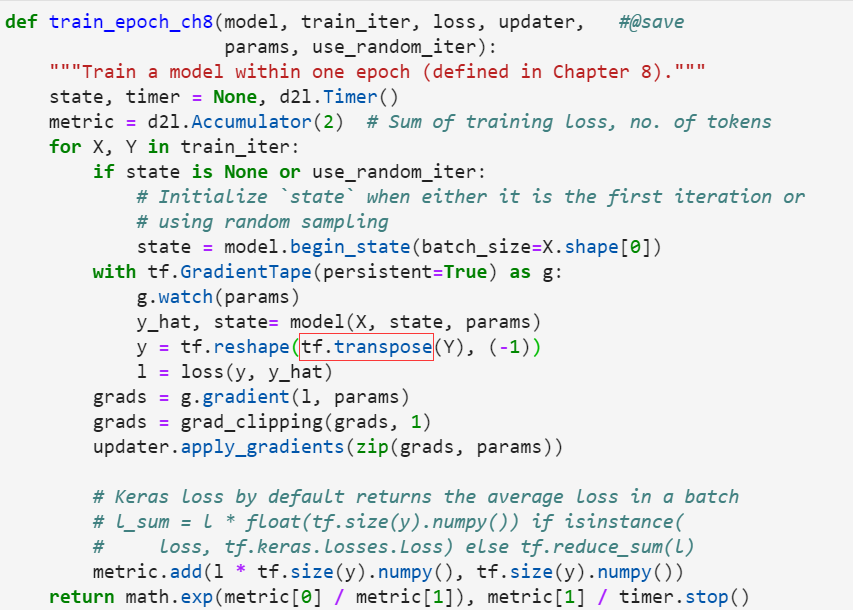
Then the training result is normal! (perplexity =1.0)
see:
great. PR please: http://preview.d2l.ai/d2l-en/master/chapter_appendix-tools-for-deep-learning/contributing.html
https://github.com/d2l-ai/d2l-en/edit/master/chapter_recurrent-neural-networks/rnn-scratch.md
@zhangjiekui
PR:
It was a nightmare when I read this chapter’s source code. Why did you make things so complicated?
I guess you missed a “$” sign in the 9.5.2.1. One-Hot Encoding section: It says “$5%”. (You might delete my comment afterwards, just wanted to let you know ![]() )
)
Am I the only one who is getting an error running the codes? Especially the codes in the “Training” section (Section 9.5.4) in line: ‘trainer.fit(model, data)’.
The error I am getting is → NoneType Object is not callable