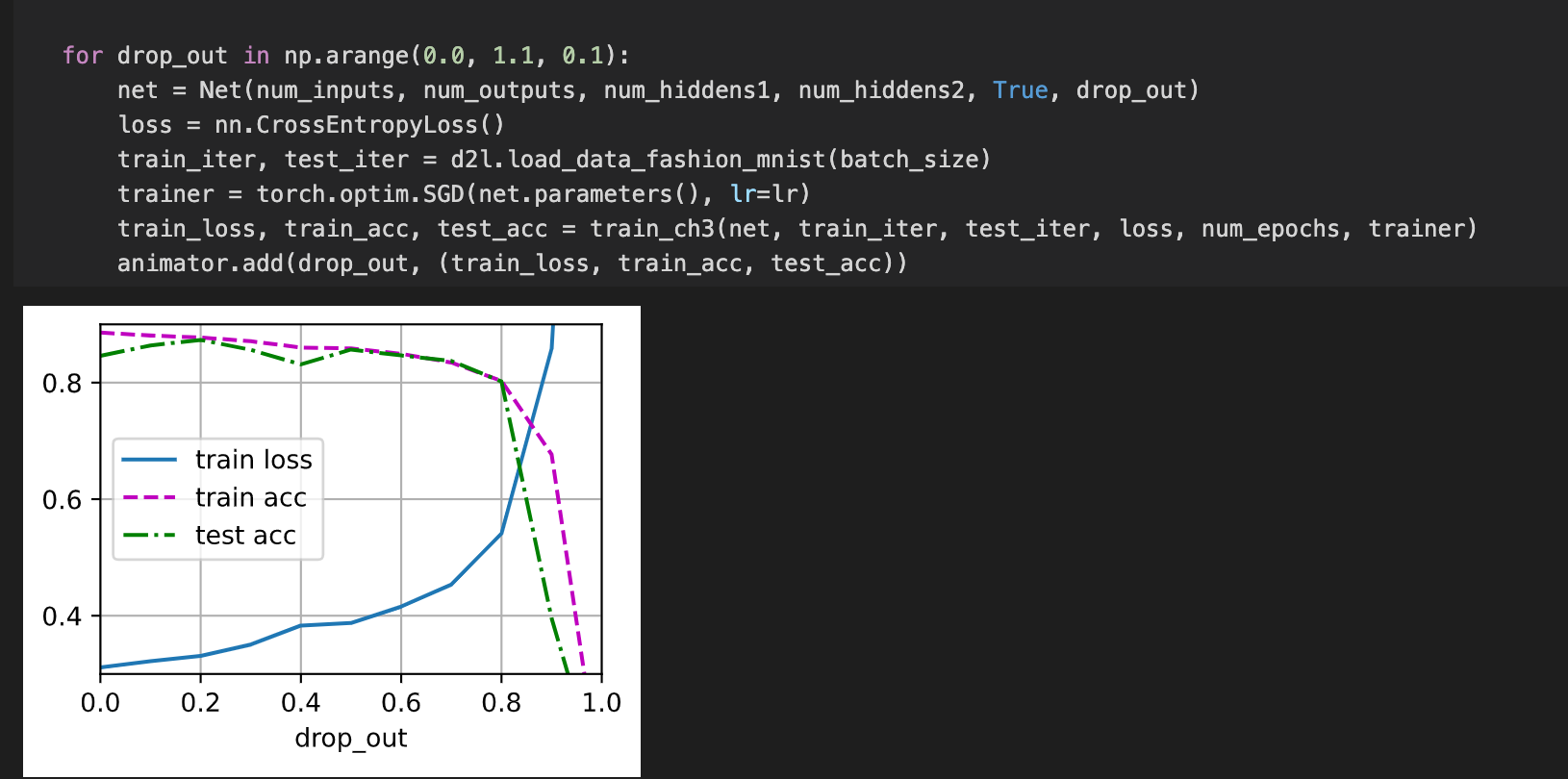
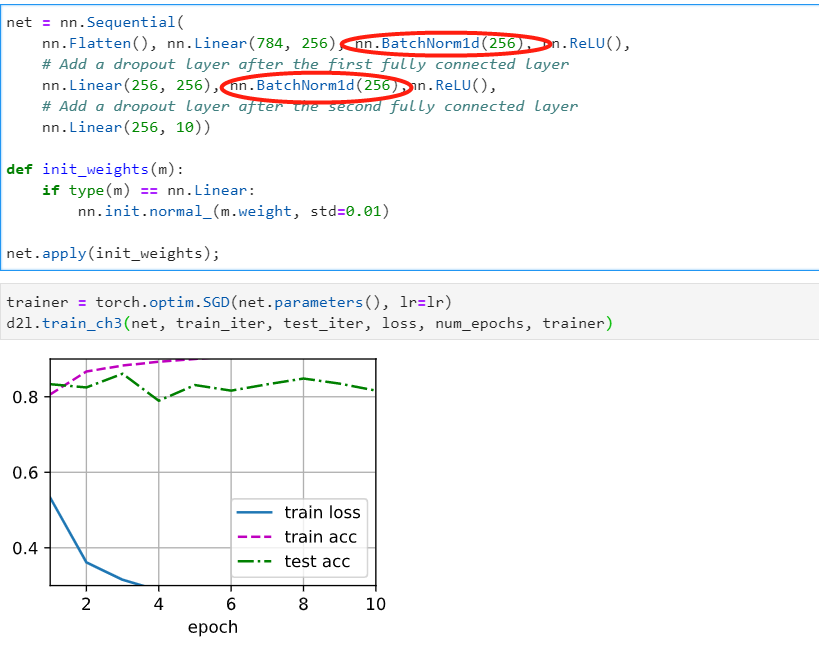
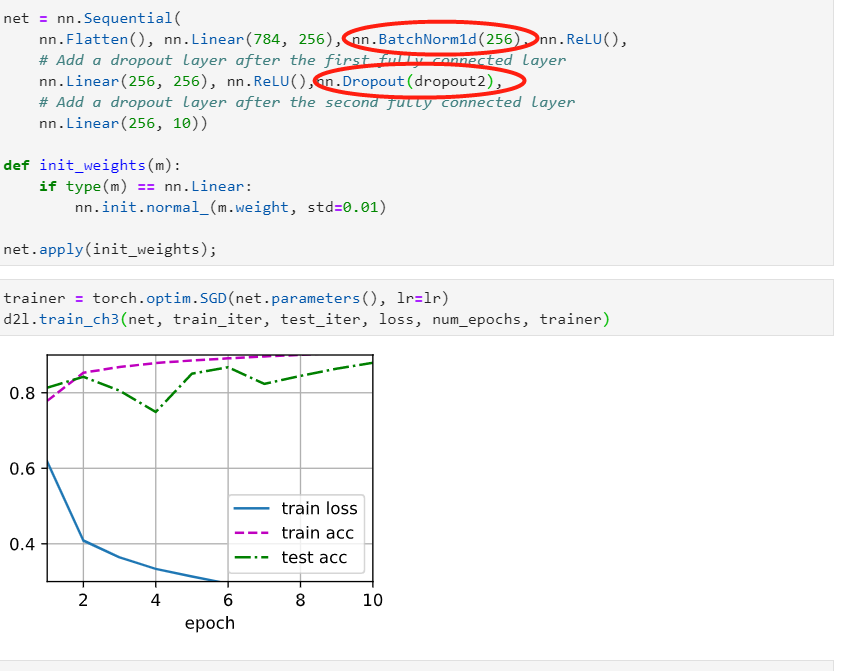
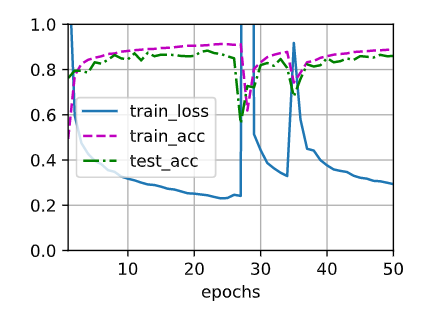
Hi,
I’m a bit confused between Dropout and Regularization. Should we use them both to train a neural network or one method is enought.
I tried using L2 regularizaion with Drop out in the exmaple in the book but I got an error
let’s leverage the efficient built-in PyTorch weight decay capability
def train_concise(wd):
#net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# Add a dropout layer after the first fully connected layer
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# Add a dropout layer after the second fully connected layer
nn.Dropout(dropout2),
nn.Linear(256, 10))
net.apply(init_weights)
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss()
num_epochs, lr = 100, 0.003
# The bias parameter has not decayed
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
with torch.enable_grad():
trainer.zero_grad()
l = loss(net(X), y)
l.backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('L2 norm of w:', net[0].weight.norm().item())
The error says “‘Flatten’ object has no attribute ‘weight’”. Can someone explain this to me???