1. Run the code in this section. Change the conditional statement X == Y to X < Y or X > Y, and then see what kind of tensor you can get.
X = torch.arange(15).reshape(5,3)
Y = torch.arange(15, 0, -1).reshape(5,3)
X == Y, X > Y, X < Y
(tensor([[False, False, False],
[False, False, False],
[False, False, False],
[False, False, False],
[False, False, False]]),
tensor([[False, False, False],
[False, False, False],
[False, False, True],
[ True, True, True],
[ True, True, True]]),
tensor([[ True, True, True],
[ True, True, True],
[ True, True, False],
[False, False, False],
[False, False, False]]))
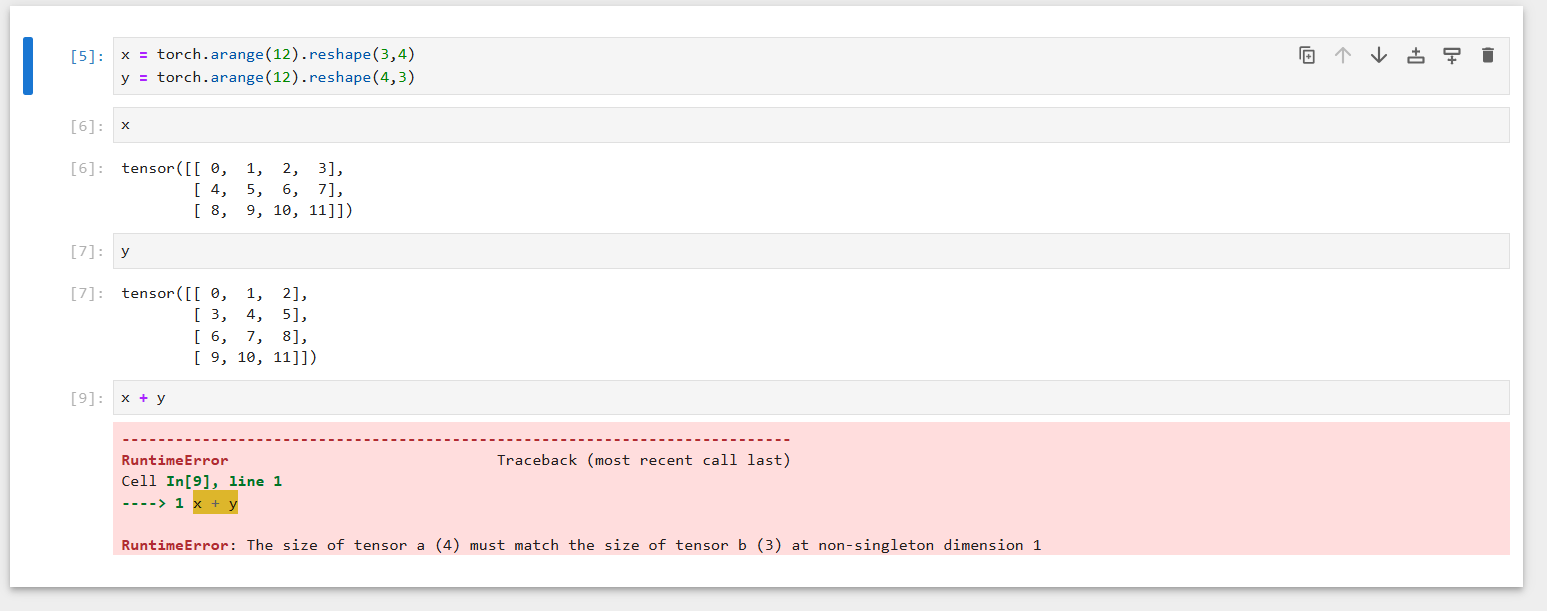
2. Replace the two tensors that operate by element in the broadcasting mechanism with other shapes, e.g., 3-dimensional tensors. Is the result the same as expected?
X = torch.arange(8).reshape(4, 2, 1)
Y = torch.arange(8).reshape(1, 2 ,4)
print(f"{X}, \n\n\n{Y}, \n\n\n{X + Y}")
tensor([[[0],
[1]],
[[2],
[3]],
[[4],
[5]],
[[6],
[7]]]),
tensor([[[0, 1, 2, 3],
[4, 5, 6, 7]]]),
tensor([[[ 0, 1, 2, 3],
[ 5, 6, 7, 8]],
[[ 2, 3, 4, 5],
[ 7, 8, 9, 10]],
[[ 4, 5, 6, 7],
[ 9, 10, 11, 12]],
[[ 6, 7, 8, 9],
[11, 12, 13, 14]]])
Yes, the result matches what I expected as well as with what I learned in this notebook