I was wondering if anyone can help me with a weird bug I’ve encountered. I’ll try to summarise. I’m training the network on fashion-mnist images resized to be 96x96 in size. I’ve adjusted the architecture appropriately, the problem is pretty strange: if I define the optimizer first and then pass it into my training function:
optimizer=torch.optim.SGD(net.parameters(), lr=lr)
train(net, all_iter, test_iter, num_epochs, lr, optimizer)
The training breaks:
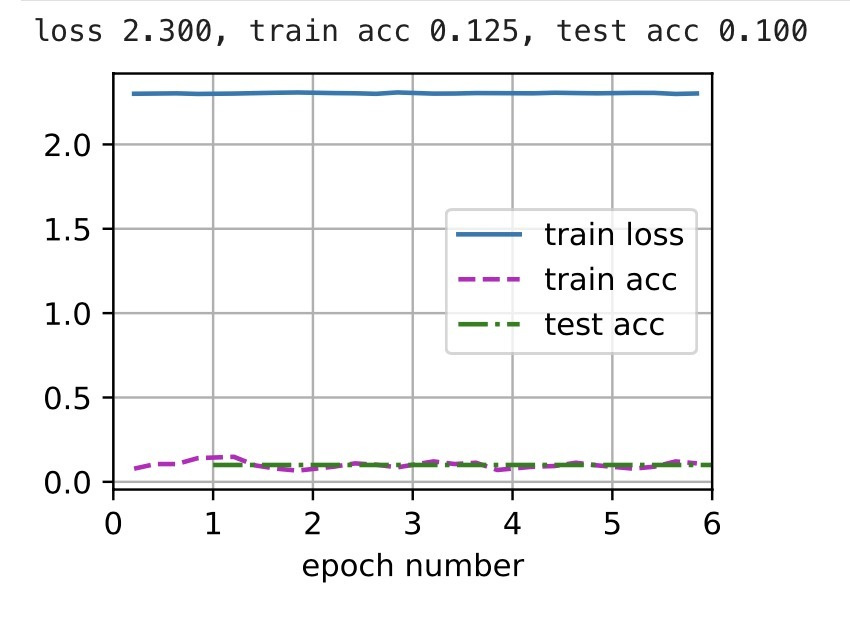
But if I copy-paste the exact same line of code that defines the optimizer inside the train function, and change nothing else:
def train(net, train_iter, test_iter, num_epochs, lr, optimizer=None, device=d2l.try_gpu()):
optimizer = torch.optim.SGD(params=net.parameters(), lr=lr)
...
Then it works fine:
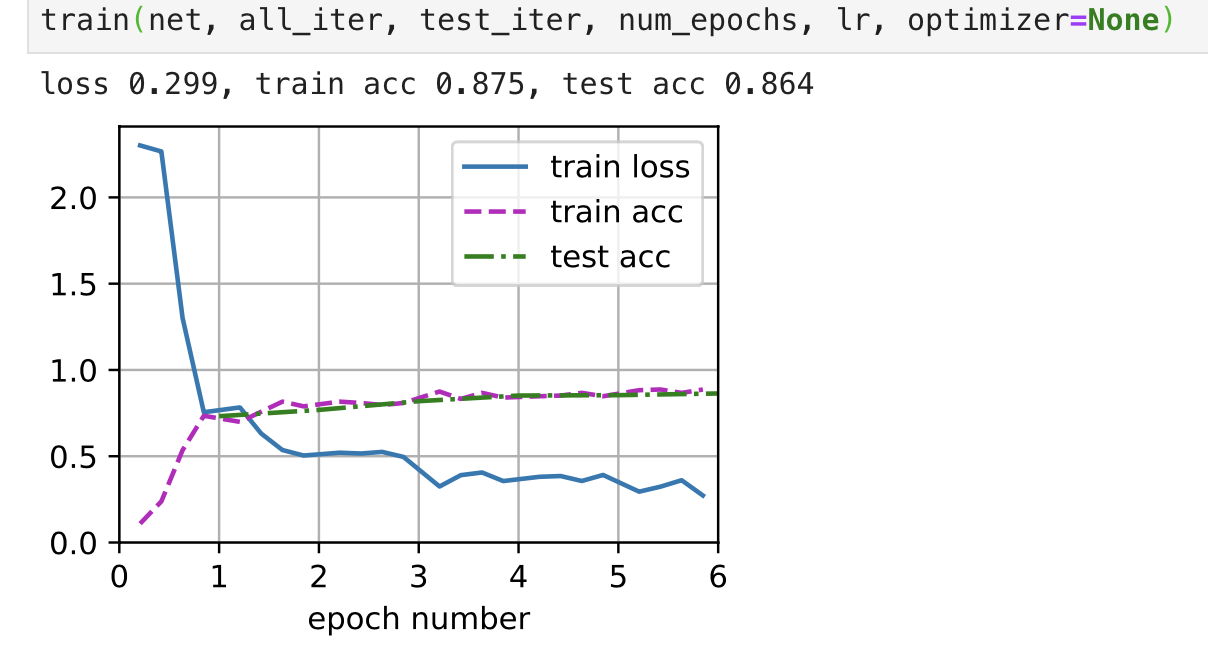
Here is my train function code - same as d2l basically, I just wanted to type it out myself:
def train(net, train_iter, test_iter, num_epochs, lr, optimizer=None, device=d2l.try_gpu()):
"""
Trains a network 'net'. Assumes that net.init_weights exists
"""
# 1: initialise weights
# net.apply(net.init_weights)
def init_weights_test(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
torch.nn.init.xavier_uniform_(m.weight)
net.apply(init_weights_test)
# 2: move model to device for training
net.to(device)
# 3: set up optimizer, loss function, and animation stuff
loss = nn.CrossEntropyLoss()
# optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
if optimizer is None:
optimizer = torch.optim.SGD(params=net.parameters(), lr=lr)
animator = d2l.Animator(xlabel="epoch number", xlim=[0, num_epochs], legend=["train loss", "train acc", "test acc"])
# 4: training loop
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
for i, (X, y) in enumerate(train_iter):
X, y = X.to(device), y.to(device)
net.train()
optimizer.zero_grad()
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
# temporarily disable grad to calculate metrics
with torch.no_grad():
train_loss = l
# import ipdb; ipdb.set_trace()
_, preds = torch.max(y_hat, 1)
train_acc = ((preds == y).sum()) / float(X.shape[0])
if (i + 1) % 50 == 0:
animator.add(epoch + (i / len(train_iter)), (train_loss, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter, device)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_loss:.3f}, train acc {train_acc:.3f}, test acc {test_acc:.3f}')
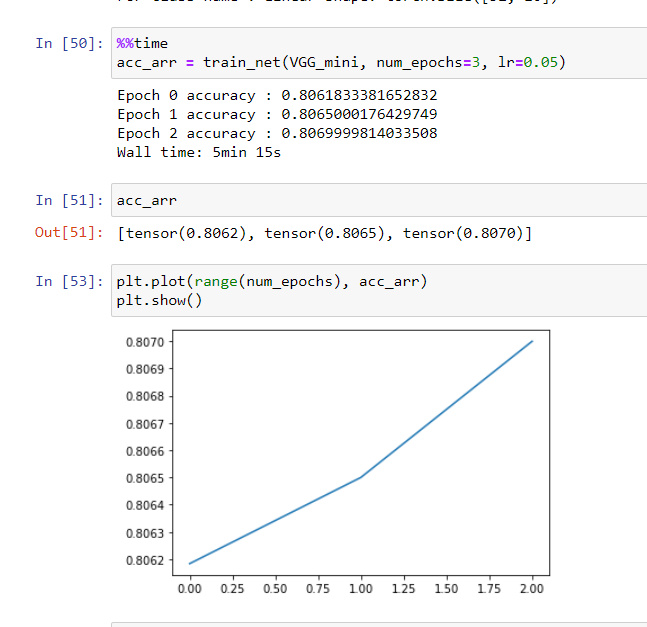
The only thing I’m training is not passing in a value for the optimizer parameter so that it takes the default value of None and is set inside the function body.
Any idea why this could cause an issue?
Can you publish all your code, and throw me a github URL?
I still wonder the part that you don’t show.
@Nish
Ok, I figured it out, I was just being stupid. Basically was doing something like this:
optimizer = optimizer(net)
net = net()
train(net, optimizer)
So of course the optimizer was not attached to the network. If you still want to laugh at my mistake you can read it all here https://github.com/NishantTharani/DeepLearning_CS231n_D2L/blob/master/d2l.ai/Ch7/vggnet.ipynb

@Nish Wow, I learnt a lot from your github and know I need to learn more.
Have stared your repo. Keep going and communicating. 
Thank you both! I finished up with this chapter by testing out VGGNet 19 on our upscaled Fashion-MNIST - https://github.com/NishantTharani/LearningDeepLearning/blob/master/d2l.ai/Ch7/vggnet19.ipynb
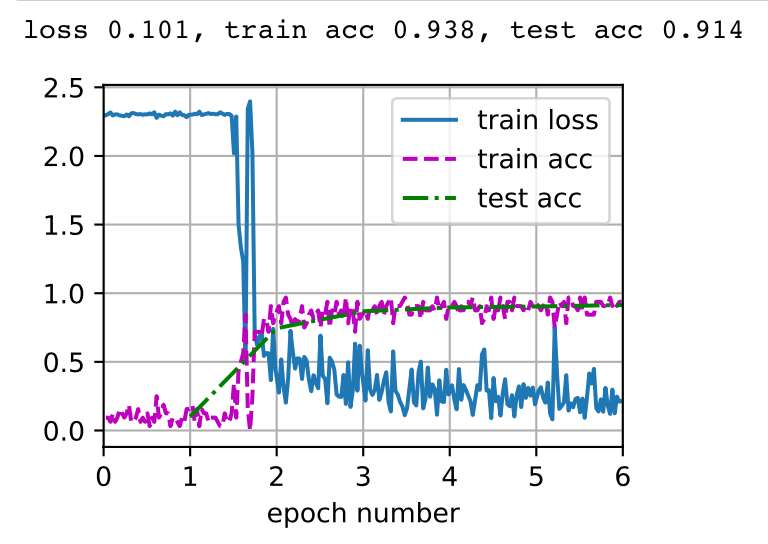
Not bad!
The vgg_block function in Pytorch is different than others. It has 3 inputs and it does not match the book description.
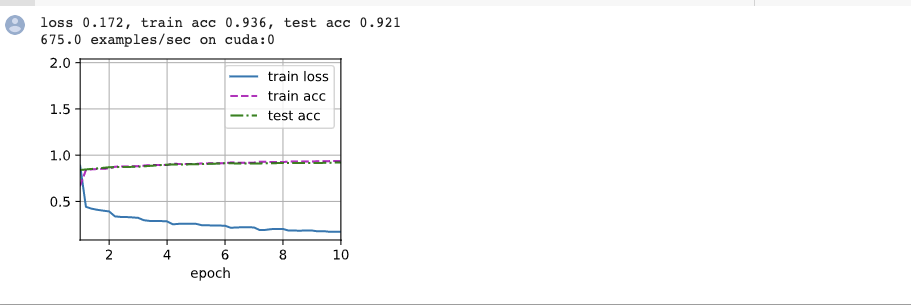
@anirudh @goldpiggy I was trying to run this in my colab environment. Any reason the training is slow.
I have rate of 675 examples/ sec however in the chapter we have 2547.7 examples/sec . I am using GPU
@sushmit86 all GPUs are not same in terms of the FLOPs they offer. Afaik Collab uses a Tesla K80 which is okay for some basic deep learning but may not be as good as some of the other high end GPU offerings.
Hence the difference!
Exercises
I am slightly frustrated at not being able to run VGG models even their reduced cousins using my gpu or kaggle. When I try my own however more often than not I am not able to train the network.
with much headache was finally able to work it out refer after question 4.
- When printing out the dimensions of the layers we only saw 8 results rather than 11. Where
did the remaining 3 layer information go?
- in maxpool
- Compared with AlexNet, VGG is much slower in terms of computation, and it also needs
more GPU memory. Analyze the reasons for this.
- it has more conv layers and the face that it has 3 linear layers. When looking at the network I found that the linear layers take most of the memory compared to conv layers.
- Try changing the height and width of the images in Fashion-MNIST from 224 to 96. What
influence does this have on the experiments?
- it wil lrun faster. This needs to be checked. I tried changing to some other value but it breaks. If its below 200 most probably you would be faced with error of too small size of image after convolution.
- Refer to Table 1 in the VGG paper (Simonyan & Zisserman, 2014) to construct other common
models, such as VGG-16 or VGG-19.
- it can be done but my GPU says hi.
VGG_19_arch = ((2,64), (2,128), (2,256), (4,512), (4,512))
VGG_16_arch = ((2,64), (2,128), (2,256), (3,512), (3,512))
finally was able to train VGG but had to remove one of the Linear layers of 4096 and replace with 512.
Colab error in this chapter
When I tried to use
model = VGG(arch=((2, 64), (2, 128), (3, 256), (3, 512), (3, 512)), lr=0.01)
to run the VGG-16 in the Colab and click the link of the chapter.
It have something run like the picture as below:
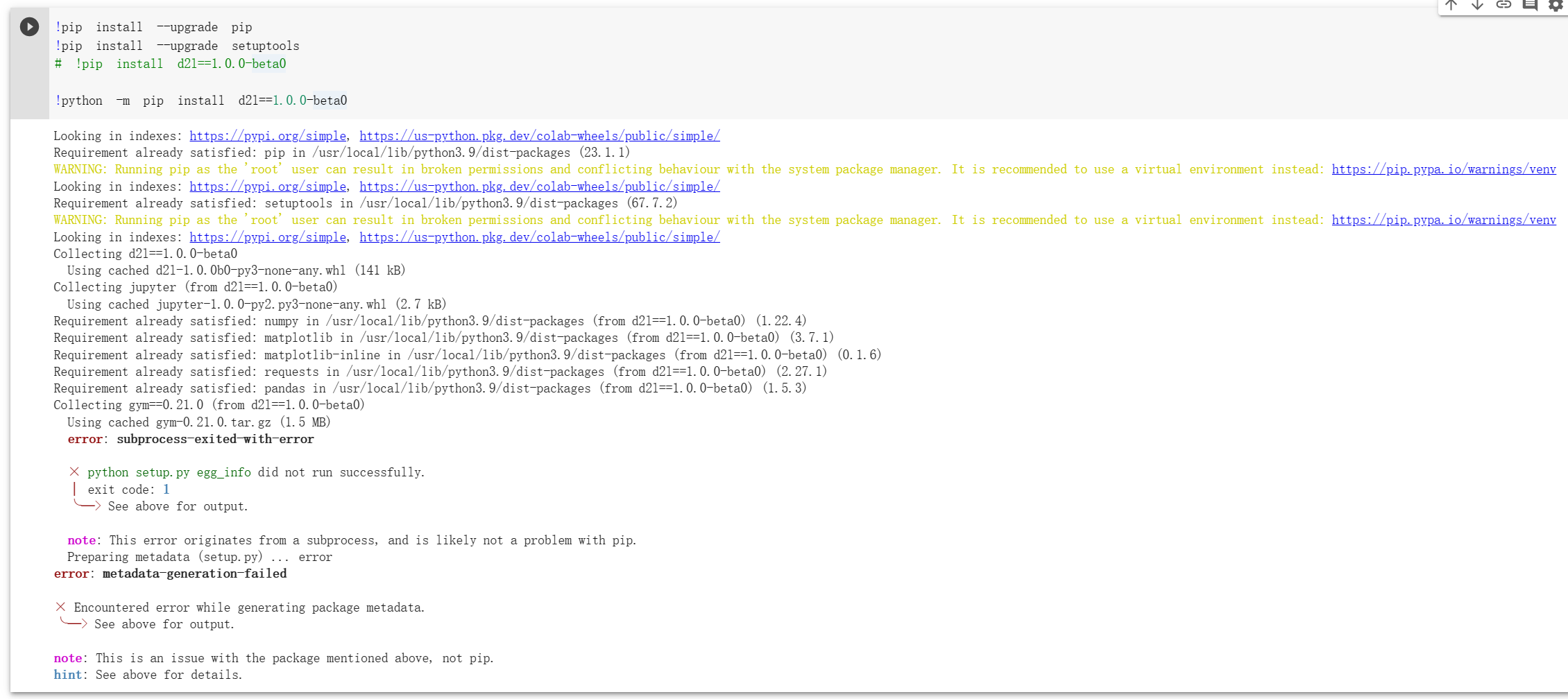
Possible resolution:
- I search the error message
python setup.py egg_info did not run successfullyin New Bing, it give me the solution as below ( not work ):
!pip install --upgrade pip
!pip install --upgrade setuptools
!pip install d2l==1.0.0-beta0
- I tried to search in Google with ‘python setup.py egg_info did not run successfully’, first StackOverflow give me the sulution as below ( not work ):
!pip install Cmake
- I tried to use verbose to lookup the detail with command
!python -m pip install d2l==1.0.0-beta0 -vvv, the output as below:

Please help me
Hi,
I am using colab to run the code. What I did is I changed the original command to this “!pip install d2l==1.0.0a0”. This version of d2l works for me, you can also try some other versions.
May I ask a (maybe trivial) question?
What is the difference of the code self.net.apply(d2l.init_cnn) in the definition of VGG, and the code model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn) in the training part?
The authors only use the first one in some cases (Section 8.1.2.3 for AlexNet), and only use the second one in some others (Section 7.6.2 for LeNet).
I thought that they were the same. However, both codes are used in this section, which proves that I was wrong.
with lazy objects in torch, one has to pass data through them first so that they can figure out the missing information such as the shape of the inputs. these are computed from the activations of the previous layers.
because not all information is present right after the lazy objects are created, the shape of the parameters is not always known.
when you call model.apply, the parameters are expected to have been created. with lazy objects, this call will fail. so one has to pass some dummy data through the system. you can do this by either calling layer_summary method and then calling the apply or do both in one step by calling apply_init.