http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
@min_xu
Hey i am having issues understanding how to tackle exercise number 4. Could you share the code you used to display this, or explain how to do it?
eg. i dont understand what data references in the image you posted
THank you
hi!
we want to do
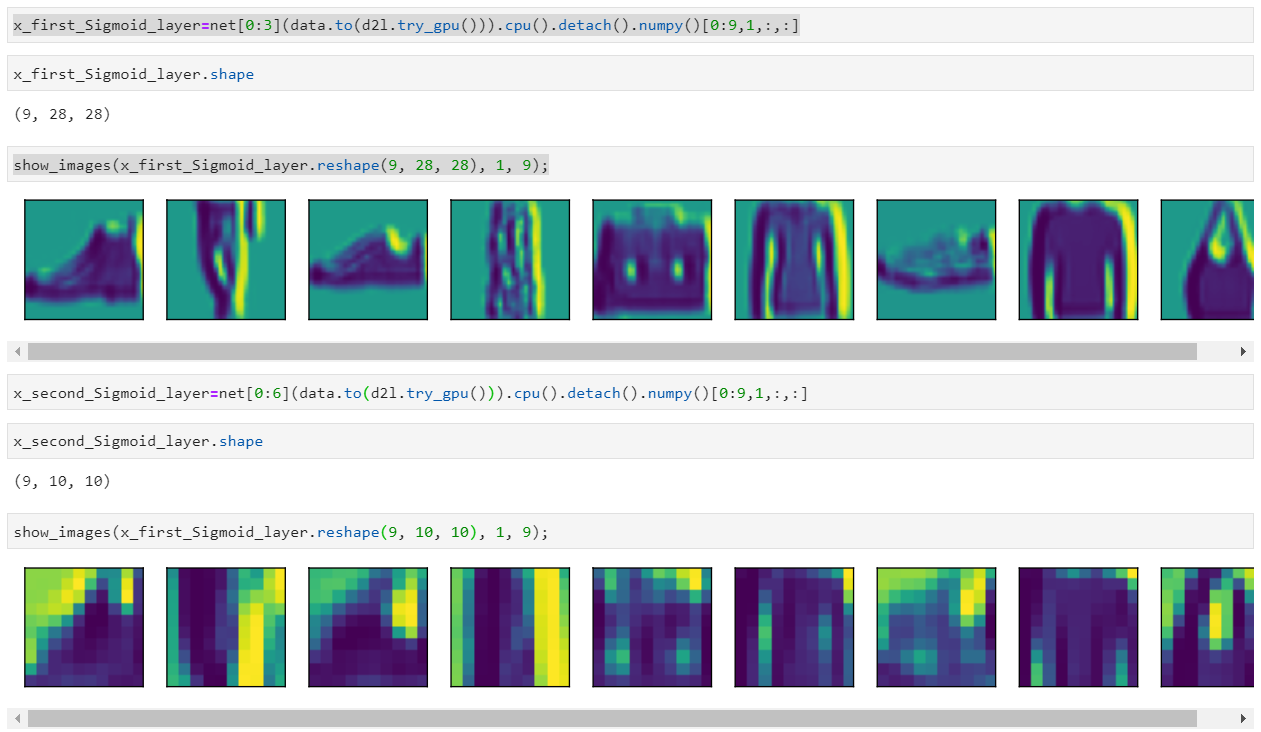
- Display the activations of the first and second layer of LeNet for different inputs (e.g., sweaters and coats).
so we can check the network
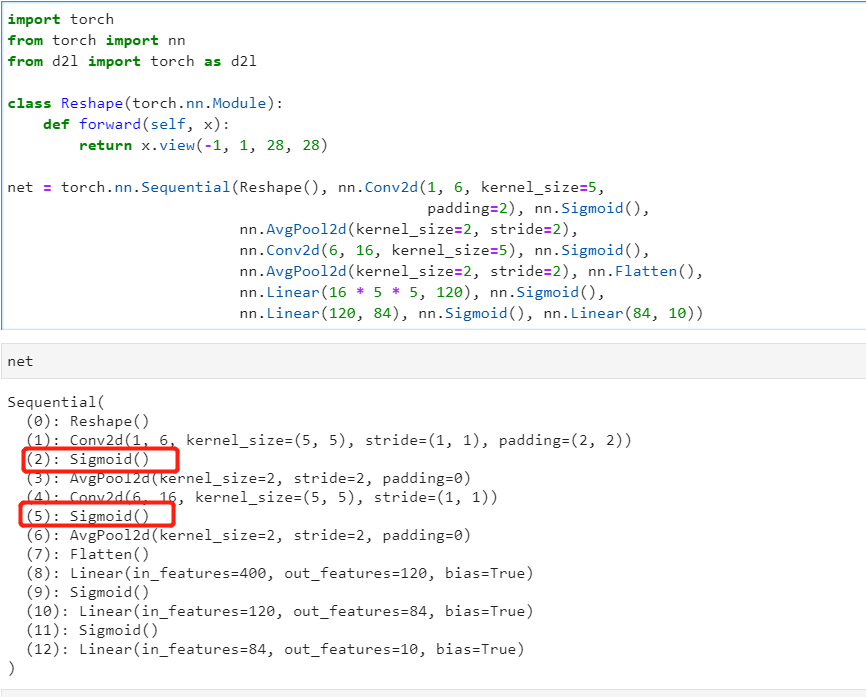
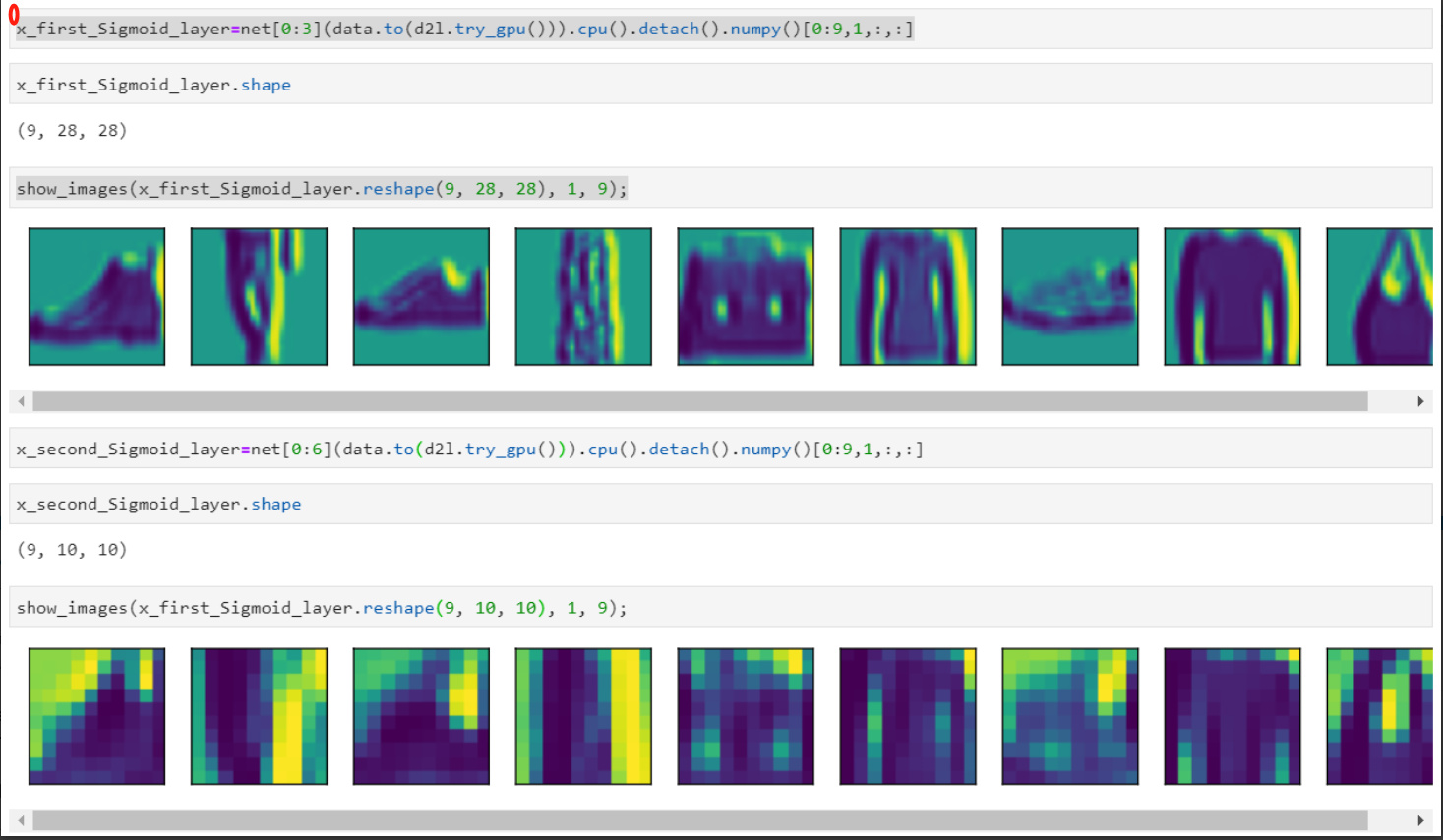
so the output of the first activations of net is net[0:3]
and the output of the second activations of net is net[0:6]
and the code is in this map,
1 Like
Hi Can anyone help with this . If we replace the init code
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
with this
for layer in model: if type(layer) == nn.Linear or type(layer) == nn.Conv2d: nn.init.xavier_uniform_(layer.weight)
Why does not it work? @goldpiggy or @anirudh any idea?
1 Like
What do you mean by “it does not work”? In what way does it not work?
If you can show what you expected to happen vs. what actually happened, the experts can try to help with it, and others (like me) can learn from it. Just saying “it didn’t work”, doesn’t work!
Exercises and my weird answers
-
Replace the average pooling with maximum pooling. What happens?
- has the almost the same .8177 and .8148
-
Try to construct a more complex network based on LeNet to improve its accuracy.
-
Adjust the convolution window size.
-
Adjust the number of output channels.
-
Adjust the activation function (e.g., ReLU).
-
Adjust the number of convolution layers.
-
Adjust the number of fully connected layers.
-
Adjust the learning rates and other training details (e.g., initialization and number of epochs.)
- my changed network.
lenet_improved = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(16, 32, kernel_size=4), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(32, 240), nn.ReLU(), nn.Linear(240,120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, 10)) -
-
Try out the improved network on the original MNIST dataset.
- did try.
-
Display the activations of the first and second layer of LeNet for different inputs (e.g., sweaters and coats).
- was this what was meant?
activation_from_first = nn.Sequential(net[0], net[1]) activation_from_second = nn.Sequential(net[0],net[1], net[2], net[3]) activation_from_first(X[0].unsqueeze(0)).shape, activation_from_second(X[2].unsqueeze(0)).shape
This is nice how did you convert any arbitrary size into image?
Good approach by in the line nn.init.xavier_uniform_(layer.weight)is it really being applied to your model which is net or aactivation layer which is different from your model.
Sorry for the late reply. What I meant was that the model fit would be bad. i.e the accuracy will be very low.
Suppose I want to tune the value of the gain argument in this function:
def init_cnn(module): #@save
"""Initialize weights for CNNs."""
if type(module) == nn.Linear or type(module) == nn.Conv2d:
nn.init.xavier_uniform_(module.weight, gain = 1.0)
How do I call the init_cnn with the gain argument in it?:
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
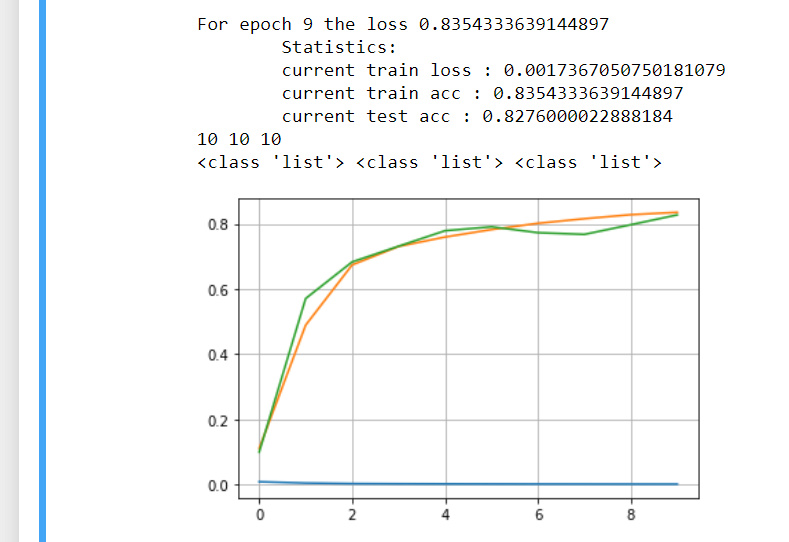
- Try out the improved network on the original MNIST dataset.
- the original: has a late conversion and settles due to gradients vanishing for sigmoid
- changing the first activation to ReLU boost it , and increase val_acc by 1.5%
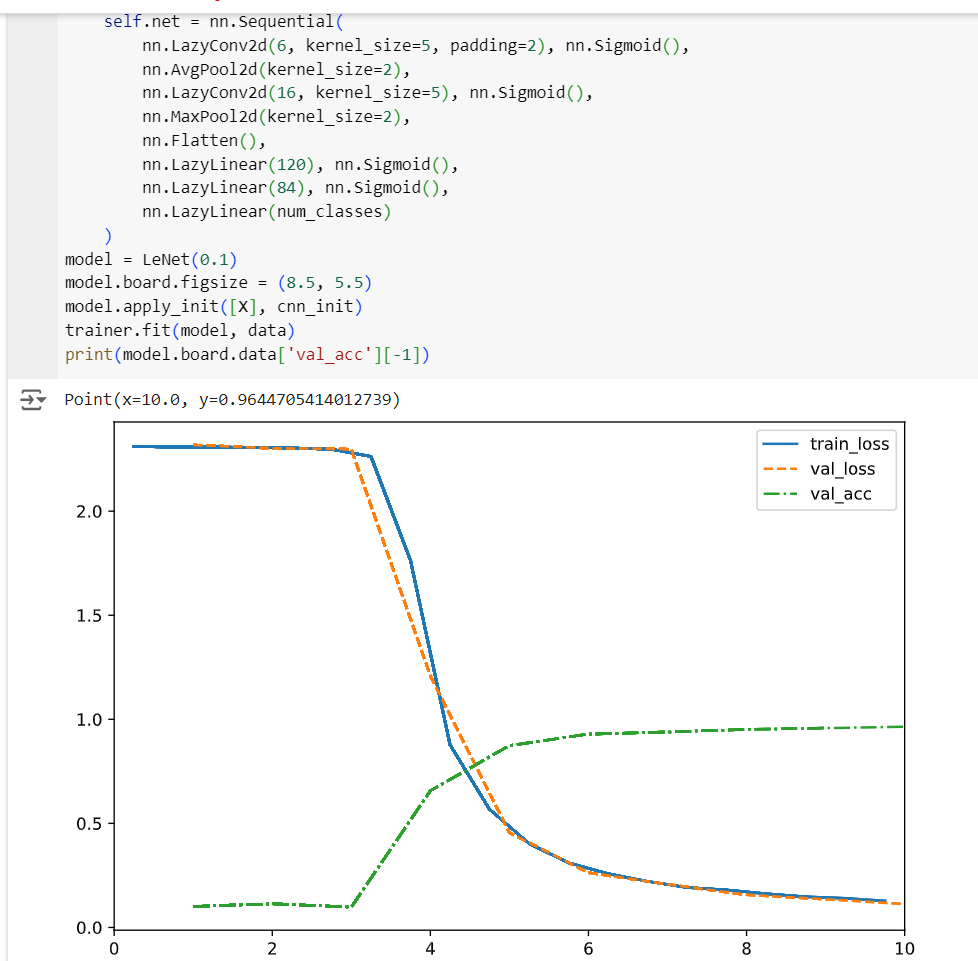
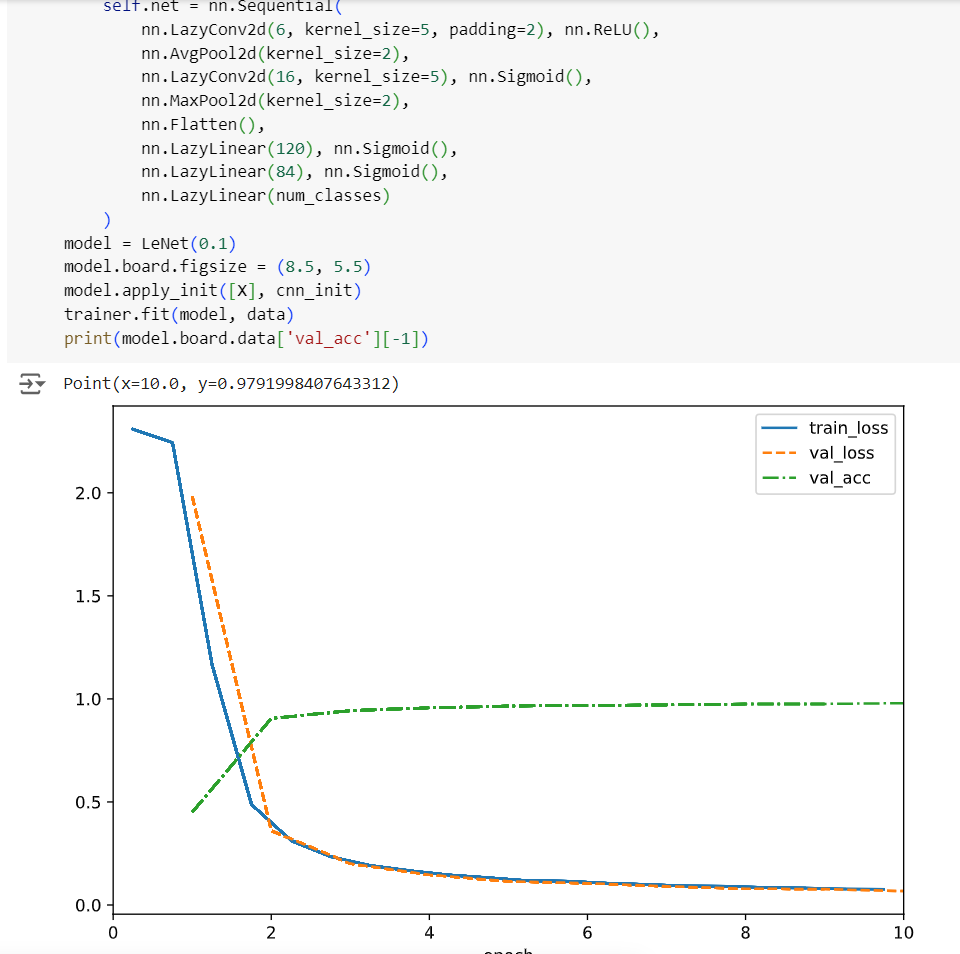
If we’re trying to stay as true to the original LeNet 5 architecture as possible, the activation functions used throughout this chapter should be nn.Tanh not nn.Sigmoid. Original paper from LeCun shows that below. The nn.Sigmoid implements the logistic function, which is just one type of sigmoid function. The way “sigmoid” is often used is kind of a misnomer…

1 Like