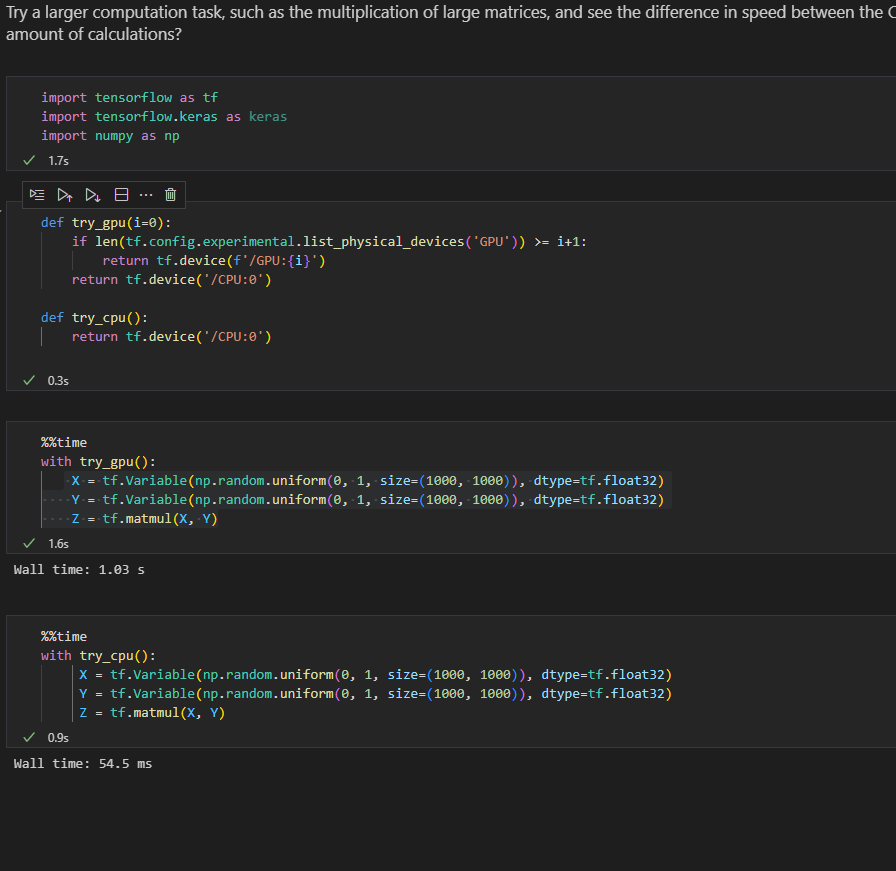
Hello,
I have been following along a course here that uses the the text as teaching material. When the course started several months ago I successfully set up a python environment with the tensorflow library that utilized the GPU on my laptop & windows 10; with jupyter and the included jupyter notebooks with the course material found in the setup section of the text I was able to run & modify the example notebooks locally without issue.
For several weeks I did not run anything locally but I did however recently update the graphics driver to 456.55 (I have a rtx mobile 2060 chipset on my laptop). That driver may contain stuff for the new ampre/3000 series nvidia cards which may or may not have something to do with my issue. Other than that I can’t really think of anything else that has changed in my environment recently.
With that said here is the issue I am having when trying to run tensorflow on my system and use the GPU; whenever I attempt to run some python (be it a jupyter notebook or native python) that uses tensorflow & the GPU everything appears to work fine at first but ultimately crashes
2020-10-06 00:20:51.475971: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library cublas64_10.dll
2020-10-06 00:20:52.171617: E tensorflow/stream_executor/cuda/cuda_blas.cc:225] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
2020-10-06 00:20:52.172931: E tensorflow/stream_executor/cuda/cuda_blas.cc:225] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
At first I thought it was the specific material I was looking at (chpt. 6 & 7) as the last time I ran examples locally they were fairly basic (chpt. 3 & 4). But when I went back to those other sections and attempted to run examples locally I encountered the same error. Now, again, things used to work fine about a month ago when I was on a the previous driver. The version of CUDA is the same (10.1) and all the dlls, windows paths, and other windows specific prerequisites are the same.
After some searching online of that error I found a forum post on the nvidia dev forums and in the suggestions for other stackoverflow posts many said that limiting the amount of GPU memory might solve the issue because they were using dynamic memory growth.
Well a clue for myself was that in the log for the command prompt when running tensorflow, my GPU was recognized with an odd amount of memory
Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4722 MB memory)
And from my memory when I ran examples about a month ago the gpu was detected with a different amount of available memory (6000 MB or thereabouts). So low and behold I set a hard memory limit following the tensorflow docs for configuring the GPU and the suggestions in the stackoverflow posts and it fixed the issue; the examples were able to run okay afterwards. For some reason setting a hard memory amount allowed my system/environment to run tensorflow and properly utilize my GPU.
I didn’t have to do this before and everything worked fine. I don’t know what is going wrong and I was wondering what the underlying issue is. Does anyone have any insight or suggestions as to what is going on or what happened?