Hi, I have 2 questions:
- In question 3: as I understood, derivative of a vector over a vector results in a matrix, since f is a vector of a, I got a vector instead, which I dont understand.
- In question 5: I have a small problem: my intention is to plot the x_grad after GradientTape, I tried but still error. Hope sb can help me out.
import matplotlib.pyplot as plt
import numpy as np
x = tf.range(-10,10,1,dtype=tf.float32)
x = tf.Variable(x)
with tf.GradientTape() as t:
y = np.sin(x)
x_grad = t.gradient(y, x)
#Plotting
x = np.arange(-10,10,0.1)
plt.figure(1)
plt.plot(x, np.sin(x), ‘r’)
plt.plot(x,np.(x_grad),‘g’)
plt.show()
#Even when I try to assign value to y, I got None result
y = tf.Variable(tf.zeros_like(x))
with tf.GradientTape() as t:
for i in range(tf.size(y)):
y[i].assign(math.sin(x[i]))
Thank you 
For question 5, you can plot ‘x_grad’ directly through pl.plt without np.
For question 5, I also ran into some similar problems, like:
TypeError: ResourceVariable doesn't have attribute ....
Y is None object.
I think the reason is that numpy ndarrays are different from tensors and they have different attributes, thus we can’t mix them up. For example, when you serve y as a numpy array in tf.gradient(y,x) method, it will return a None Object.
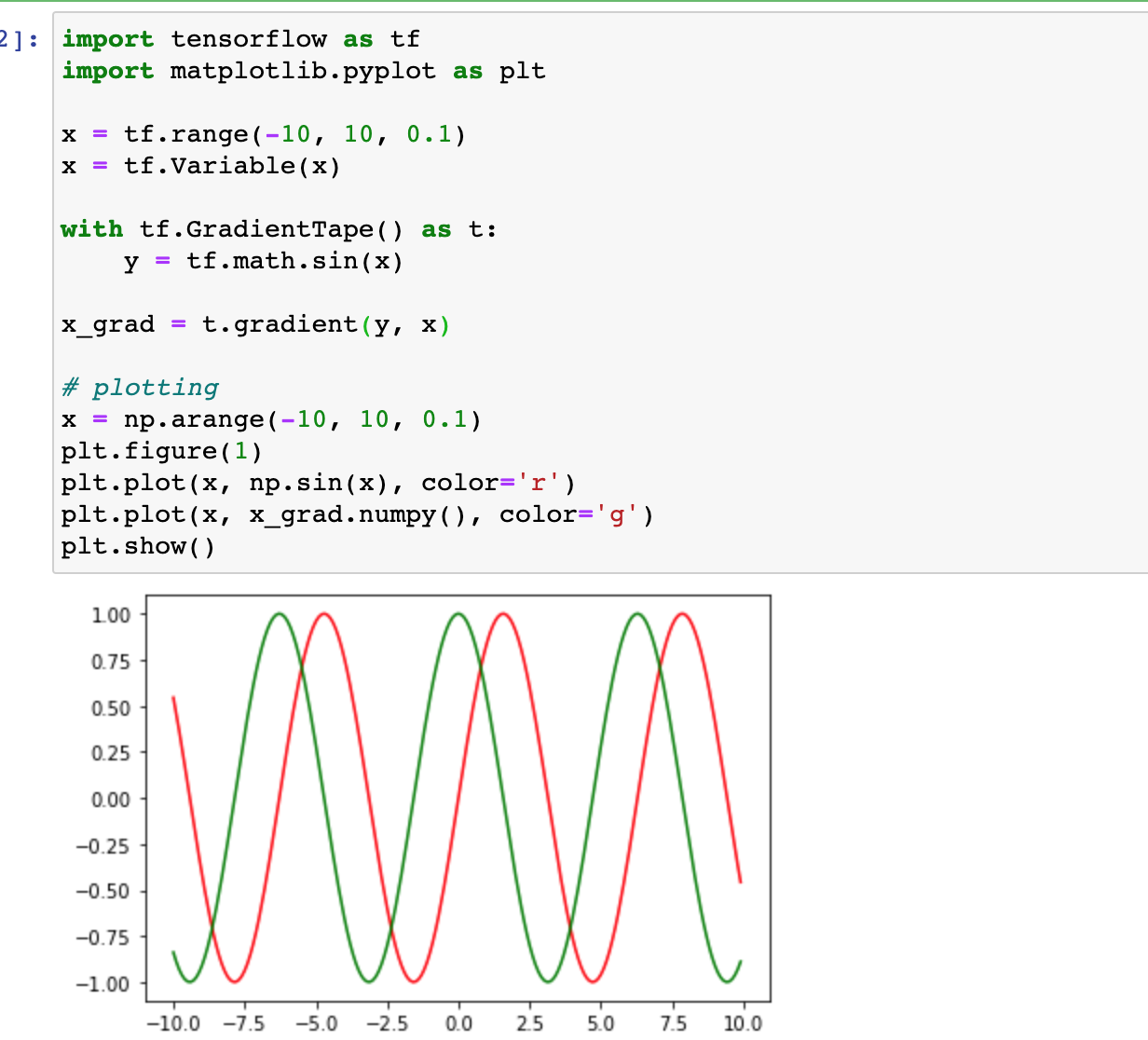
Also, you can refer to my code below:
import tensorflow as tf
import matplotlib.pyplot as plt
x = tf.range(-10, 10, 0.1)
x = tf.Variable(x)
with tf.GradientTape() as t:
y = tf.math.sin(x)
x_grad = t.gradient(y, x)
# plotting
x = np.arange(-10, 10, 0.1)
plt.figure(1)
plt.plot(x, np.sin(x), color='r')
plt.plot(x, x_grad.numpy(), color='g')
plt.show()
It works on my local machine.
x.t*x is equivalent to x^2 in vector notation. If you take a vector x, then x.T (the transpose of x), and multiply them, you end up with a scalar equivalent to x^2. So really this is taking the derivative of 2x^2, which is 4x.
Heres a longer-winded answer on this as well - https://math.stackexchange.com/questions/132415/vector-derivation-of-xtx
They only discuss the x.T*x case, but multiplying by a scalar 2 just ends up again working out to 4x instead of the 2x they show there.
In Linear Algebra section, there is a formula: (X.T*X)' = 2X, then multiply both side by 2.
About Question3: f(x) is a scalar function, not a vector function. You can get the detail in the link:
https://en.wikipedia.org/wiki/Matrix_calculus#Scalar-by-vector
In question 3 like someone asked previously, the derivative of a vector over a vector is a matrix,
but after calling the gradient method we have a vector,
Is the reason why related to the Backward for Non-Scalar Variables paragraph.
They say:
" Here, (our intent is ) not to calculate the differentiation matrix but rather (the sum of the partial derivatives computed individually for each example ) in the batch."
I think the vector returned by the gradient method is the sum of each column of the matrix generated by the derivative, but I am not totally sure about it…
typo: “an dot product of x and x is performed”? Should be “a dot product” ?
I believe you are mainly right. The way I understand it is that we have a vector y = [y1,y2, … , yn] and a vector x. If we calculate the derivative of y with respect to x, we will end up with a matrix called the Jacobian. However, since we want the result to be a vector not a matrix, we sum all the elements in vector y, then we calculate the derivative of y with respect to x. Something like this:
y = [y1,y2, … , yn]
y = y1 + y2 + … + yn # Same as y = tf.reduce_sum(y)
dy / dx
There is typo in the doc which causes a lot of confusion. The last statement in 2.5.4, d_grad == d / a should be evaluated to True.
y = ax^b= 2x^Tx = 2x^2
dy/dx = (a*b)x^(b-1) = (2 *2)x^(2-1) = 4x