sum = data.isna().sum()
data = data.drop(columns=sum.index[sum.argmax()])
当使用Pandas2.*版本的时候,将无法通过inputs.mean()直接进行填充。需要选中相应的列,计算均值,然后相应处理。 其次,在Pandas2.*版本下,pd.get_dummies()返回值将是True与False的形式,但与1, 0是通用的。
如果遇到inputs = inputs.fillna(inputs.mean())报错:TypeError: can only concatenate str (not “int”) to str
可以采用:inputs = inputs.fillna(inputs.select_dtypes(include=‘number’).mean())
解决问题
you can also use the Pandas version 1.5.0 to solve this problem(TypeError: can only concatenate str (not “int”) to str) ![]()
如果遇到 [AttributeError: module ‘numpy’ has no attribute ‘bool’?]
在版本 NumPy 1.24.0 中,已弃用的 np.bool 被完全删除。这意味着您使用的 NumPy 版本删除了已弃用的方法,并且您使用的库未更新以匹配该版本(使用类似 np.bool 而不是 < a i=5>).bool
您可以使用旧版本的numpy (删除之前),但该问题尚未修复。 最新的是 1.23.5。
#pip install numpy==1.23.5
In pandas 2.x, if you encounter issues with str and int types,just tweak the line
inputs = inputs.fillna(inputs.mean())
to
inputs = inputs.fillna(inputs.mean(numeric_only=True))
如果是新版本panda 这行代码inputs = inputs.fillna(inputs.mean()) 会报如下错误:
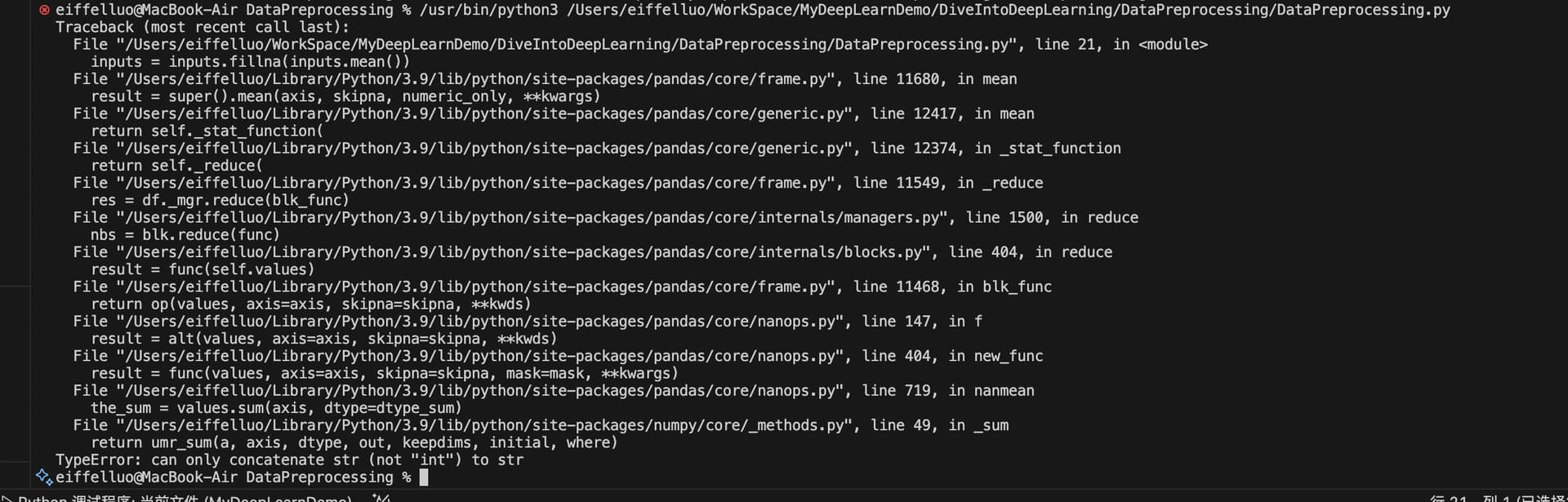
是因为panda新版本对fillna做了调整,旧版本是默认忽略str的。 改成如下代码就好了
inputs = inputs.fillna(inputs.mean(numeric_only=True))
d= data.dropna(axis=1,thresh=len(data)-data.isna().sum().max()+1)
np.array(d)
下面是我的练习,如果有错误或者更好的方法欢迎指正
#下面是练习
test_data_file=os.path.join('..','data','test_data_pre_process.csv')
with open (test_data_file,'w',) as w:
w.write('Animal,Height,Weight,Age\n')
w.write('cat,10,8,3\n')
w.write('dog,15,15,6\n')
w.write('duck,6,8,NA\n')
w.write('mouse,5,1,NA\n')
w.write('NA,0.5,0.01,0.01\n')
test_data=pd.read_csv(test_data_file)
print(test_data)
#找出需要删除的那一列
need_to_delete=''
na_max=0
for column_name, column_data in test_data.iteritems():
current_na_nums=column_data.isna().sum()
if(current_na_nums>na_max):
need_to_delete=column_name
na_max=current_na_nums
test_data.drop(columns=[need_to_delete], inplace=True)
print(test_data)
test_data.fillna('bug')
out=test_data.iloc[:,1:3]
T=torch.tensor(out.to_numpy(dtype=float))
T
どうもありがとうございました!!非常感谢!!
额外考虑了缺失值数量最大且相等的列
max_na_num = inputs.isnull().sum().max()
for i in inputs.columns:
if inputs[i].isnull().sum() == max_na_num:
inputs.drop(columns = i,axis = 1,inplace=True)