https://d2l.ai/chapter_natural-language-processing-pretraining/bert-dataset.html
I believe there is a subtle bug in the function _replace_mlm_tokens, where the to-be-masked word should be replaced with a random word. Specifically the else part of the following code is incorrect.
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
else:
masked_token = random.randint(0, len(vocab) - 1)
Here the variable masked_token is set to an int object representing the index of the replacement word into the vocabulary (not the replacement word itself, as it should be). As a result the replaced token list (variable mlm_input_tokens) will have value like this
['<cls>', 'as', 'with', 'many', 'predators', 11709, 'a', 'cougar', 18225, 'attack', 'if', 14079, '<mask>', '<mask>', 'a', 'fleeing', 'human', 'stimulates', 'their', 'instinct', 'to', 'chase', ',', 'or', 'if', 'a', 'person', '"', 'plays', 'dead', '<mask>', '<sep>', 'standing', 'still', 'may', 'cause', 'the', 'cougar', 'to', 'consider', 'a', 'person', 'easy', 'prey', '<sep>']
The int objects 11709, 18225 and 14079 are the buggy replacements. They should have been str objects containing a randomly chosen word. Since there are no such int objects in vocab.token_to_idx, they are later on treated as <unk> tokens.
The correct version should be
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
else:
masked_token = random.choice(vocab.idx_to_token)
2 Likes
Just a matter of taste (coding style), but we can refactor
mlm_input_tokens = [token for token in tokens]
to be more Pythonic as
mlm_input_tokens = tokens[:]
thanks for solving my confusion 
Thanks, that’s a good catch! A fix is on the way.
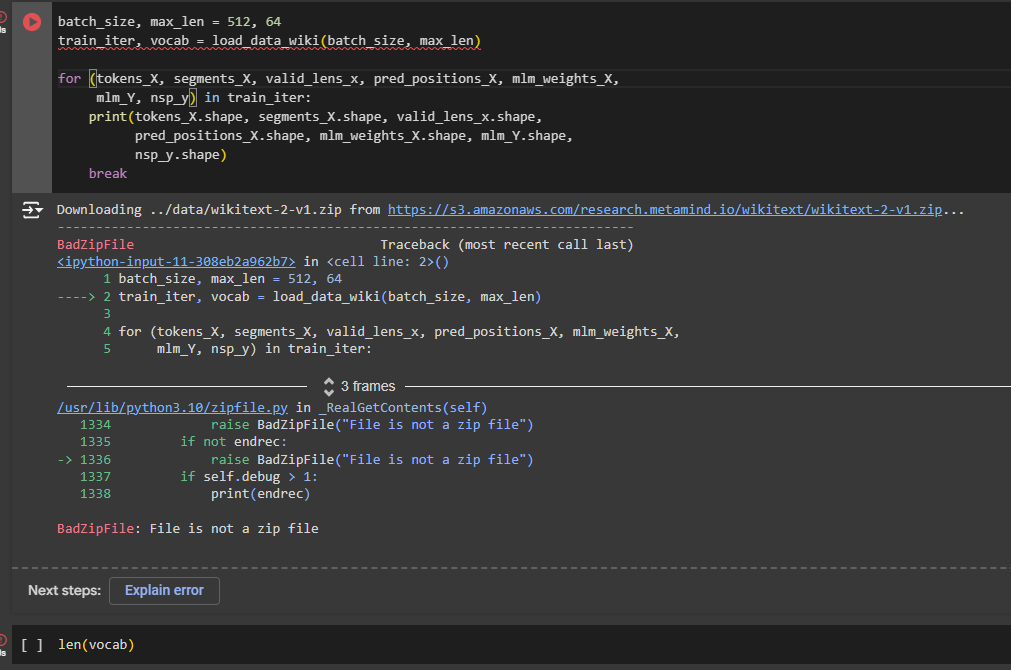
Same problem here. Does anyone know how to fix this?