https://d2l.ai/chapter_natural-language-processing-pretraining/word-embedding-dataset.html
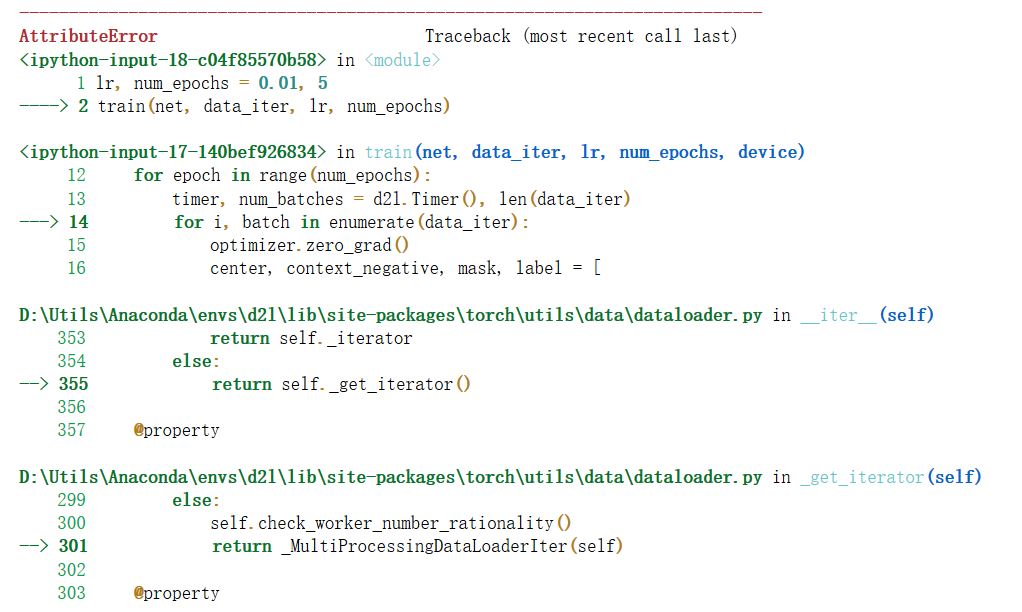
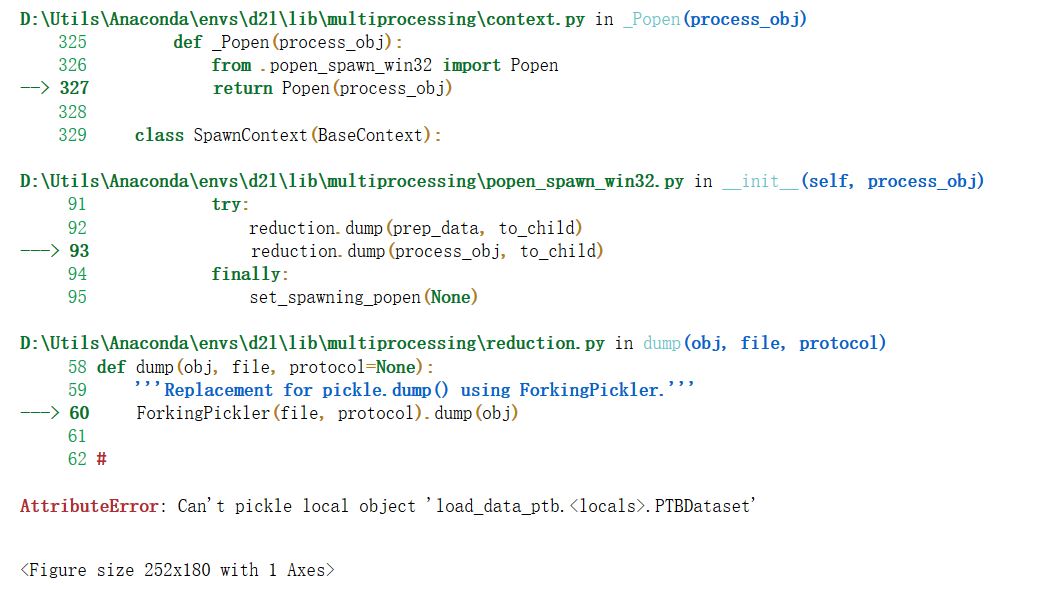
I encountered a problem while repeating the " 14.3.4. Putting All Things Together" part. It seems that there’s something wrong in the ForkingPickler() function of reduction.py. The error messages are as follows. The problem still confuses me after searching the Internet.I’m a rookie and I really need your guidance.Looking forward to your reply.

for the batchify function, it will run as a collector, to collect 512 samples and feed them into batchify function. in this case, each batch may have different shape, since the number of context words is randomly chosen.
1 Like
Why is the window size for each context randomly selected? Why can’t we keep the window_size as fixed and change it only for tokens at the beginning or end of the sentence?
“For a central and context word pair, we randomly sample K noise words ( K=5 in the experiment).” So the total number of random samples per example is dependent on the number of context words. Why don’t we simply sample a fixed number per central word instead? In other words,
why do we:
while len(negatives)<len(contexts) * K:
and not:
while len(negatives)< K:
I just cannot understand what RandomGenerator is doing,or why we make such a class?why not just random choice directly from random.choices?
set num_wokers=0 will help
sampling_weights in negative sampling is generated from “token frequences before subsampling” , why not generate it from “token frequences after subsampling”? The initial paper doesn’t give an explanation.
it will lose diversity if uses fix window size, this acts as the ‘shuffle’ operation during iterations as per epoch