https://d2l.ai/chapter_multilayer-perceptrons/kaggle-house-price.html
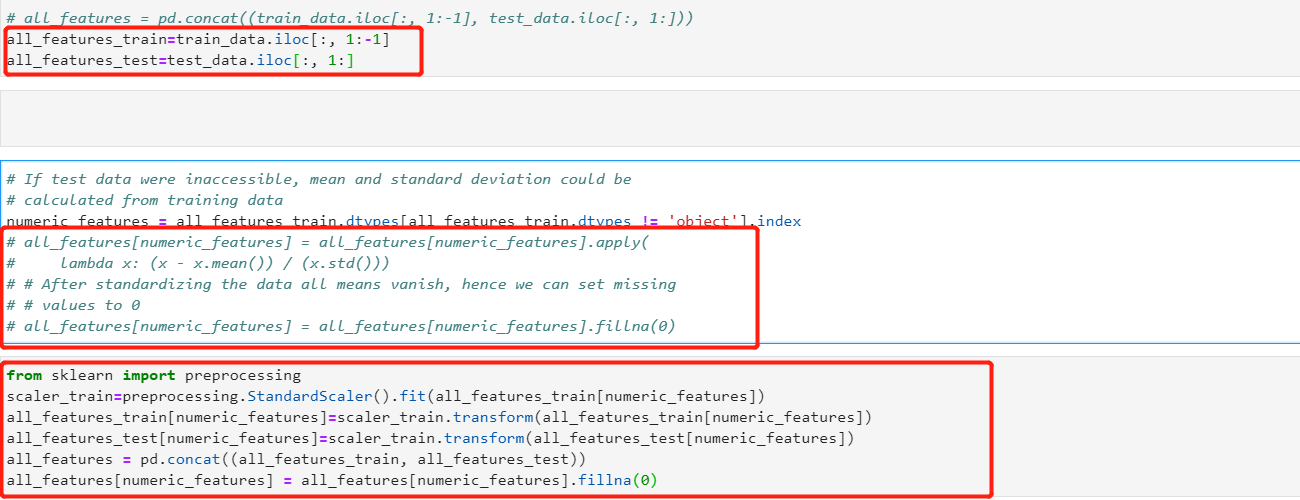
Hi, when doing standardization one would need to first calculate mean and std of the train set, and then use that mean and std to standardize the test set. Otherwise you have information leakage from training data to test data.
Hi @Irma_Ravkic, great catch! I agree with you about the information leak! Would you like to be a contributor?
Thanks. Yes, sure, I can change that section (and if I see something else on the way).
Irma
When I try to use sgd instead of Adam, I get nan as the rmse value at the end. I ran the code using the google colab link provided so there is no implementation problem from my side. Why doesn’t sgd work here?
Hi @gpk2000, great question. For gradients with significant variance, we may encounter issues with divergence. That is why you saw the NAN at the end. Adam and other optimization methods alleviate the problem: https://d2l.ai/chapter_optimization/adam.html.
1 Like
In both the pdf and colab version it seems that this issue was fixed and executed in the “Data Preprocessing” passage of this section, is that true?
What do you think about:
?