Q2,
class ParallelBlock(nn.Module):
def init(self,*args):
super().init()
self.linear = nn.Linear(10+10,10)
self.input_net = args
def forward(self,X,X2):
X = self.input_net[0](X)
X2 = self.input_net[1](X2)
return self.linear(torch.cat((X,X2),dim=1))
p = ParallelBlock(MLP(),MLP())
p(X,torch.rand(2,20))

Can someone explain to me in the following code?
class MLP(nn.Module):
# Declare a layer with model parameters. Here, we declare two fully
# connected layers
def init(self):
# Call the constructor of theMLPparent classBlockto perform
# the necessary initialization. In this way, other function arguments
# can also be specified during class instantiation, such as the model
# parameters,params(to be described later)
super().init()
self.hidden = nn.Linear(20, 256) # Hidden layer
self.out = nn.Linear(256, 10) # Output layer# Define the forward propagation of the model, that is, how to return the # required model output based on the input `X` def forward(self, X): # Note here we use the funtional version of ReLU defined in the # nn.functional module. return self.out(F.relu(self.hidden(X)))
How do we use the forward function directly with the object of MLP. as in
net = MLP()
net(X)
How are we using forward directly rather than
1 replynet.forward(X)
@sushmit86 forward is called inside the built in metod __call__ . You can look at this function in pytorch source code and see that self.forward is called inside this method.
The reason for not calling forward explicitly by net.forward is due to the hooks being dispatched in __call__ method.

Hi,
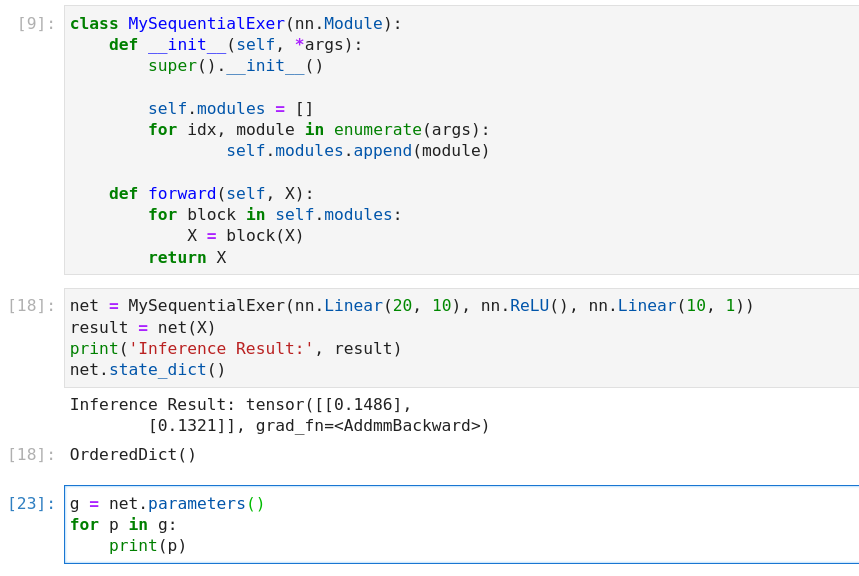
class MySequential(nn.Module):
def init(self, *args):
super().init()
for block in args:
# Here, block is an instance of a Module subclass. We save it
# in the member variable _modules of the Module class, and its
# type is OrderedDict
self._modules[block] = block
is it typo to use the module class as the key and value in the same time? or you have better reasons?
thx

It’s a typo. Keys are supposed to be ids of [str] type - not Module’s.
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, block in enumerate(args):
self._modules[str(idx)] = block
...
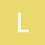
Hi,
I tried to use Python’s list to implement class MySequential. Here are the codes:
class MySequential_(nn.Module):
def init(self, *args):
super().init()
self.list = [block for block in args]
def forward(self, X):
for block in self.list:
X = block(X)
return X
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)
tensor([[ 0.2324, 0.0579, -0.0106, -0.0143, 0.1208, -0.2896, -0.0271, -0.1762,
-0.0771, 0.0069],
[ 0.3362, 0.0312, -0.0852, -0.1253, 0.1525, -0.1945, 0.0685, 0.0335,
-0.1404, -0.0617]], grad_fn=)
And the output looks fine to me. I am curious about the problem of using list to replace self._modules in implementing MySequencial?

Hi! I found a typo in Section 5.1.1 of the PyTorch version. In the code snippet used to define class MLP, inside the __init__() function there is a comment that reads “# Call the constructor of the MLP parent class ‘Block’ to perform […]”. The correct name of the parent class is ‘Module’ (‘Block’ is the mxnet version).
Great book! Thanks!

what is the answer for Q1:
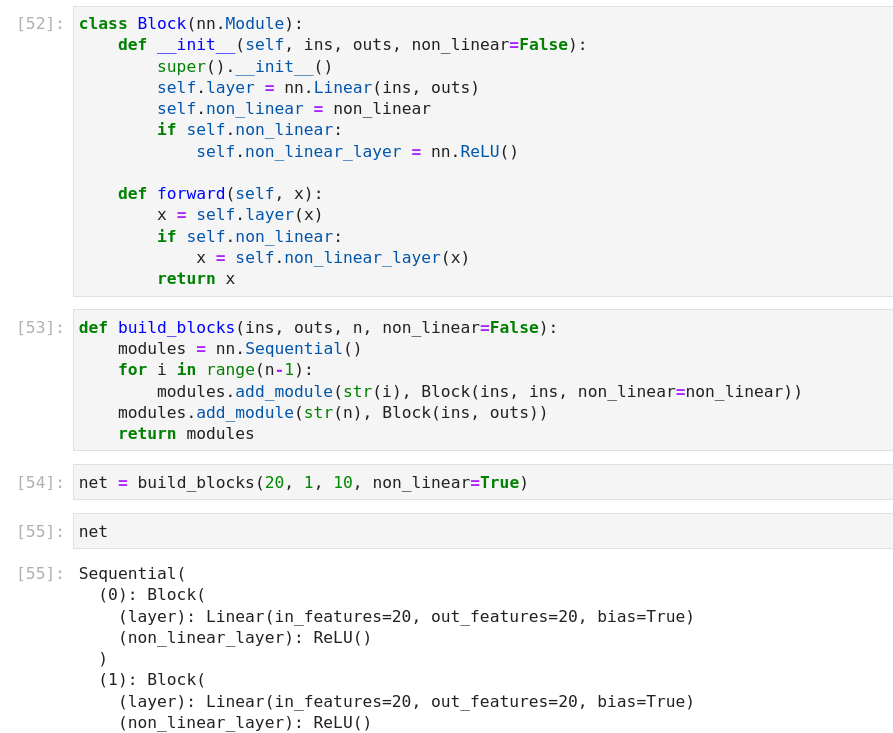
Q3
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.out = nn.Linear(256,20)
def forward(self, X):
return self.out(F.relu(self.hidden(X)))
class Factory(nn.Module):
def __init__(self, k):
super().__init__()
modules=[]
for i in range(k):
modules.append(MLP())
self.net = nn.Sequential(*modules)
def forward(self, X):
return self.net(X)
net = Factory(3)
X = torch.rand(2,20)
out = net(X)
print(net)
Factory(
(net): Sequential(
(0): MLP(
(hidden): Linear(in_features=20, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=20, bias=True)
)
(1): MLP(
(hidden): Linear(in_features=20, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=20, bias=True)
)
(2): MLP(
(hidden): Linear(in_features=20, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=20, bias=True)
)
)
)
Is this correct?

In section 5.1.1 it says:
For example, the first fully-connected layer in our model above ingests an input of arbitrary dimension but returns an output of dimension 256.
The “model above” is defined as: nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10)) .
From what I understand, the first fully connected layer in this model is nn.Linear(20, 256), and it takes an input of dimension exactly 20, no more and no less.
Why is it stated that this layer takes an input of arbitrary dimension? What am I missing here?
1 reply
Thanks, @gphilip for raising this. Most part of the book has common text and we are trying to fix issues like these where the frameworks differ in design. Feel free to raise any other issues if you find something similar in other sections on the forum or the Github repo. Really appreciate it!
This will be fixed in #1838

list?
the concatenated output of both networks in the forward propagation. This is also called a
parallel block.
class parallel_mlp(nn.Module):
def __init__(self, block1, block2):
super().__init__()
self.block1 = block1
self.block2 = block2
def forward(self, X):
first = self.block1(X)
second = self.block2(X)
print(first, second)
return torch.cat((first, second))
a factory function that generates multiple instances of the same block and build a larger
network from it.

For exercise1:
I found if I just use the list to store modules, there is nothing in net.state_dict() and net.parameters()
Here are the example:

Hi,
In the custom Mysequential class, why we need idx to be str ? ‘self._modules[str(idx)] = module’
and as the comment of this line, you meant ‘_module’ is a type of Ordereddict right? Instead of module.

class parallel_block(nn.Module):
def __init__(self, net1, net2):
super().__init__()
self.net1 = net1
self.net2 = net2
def forward(self, X):
return torch.cat((self.net1(X), self.net2(X*2)), 0)
parallel_block(MLP(), MLP())

My solutions to the exs: 6.1

My Solution to Q3:
class DaisyX(nn.Module):
def __init__(self, genericModule: nn.Module, chain_length=5):
super().__init__()
for idx in range(chain_length):
self: nn.Module
self.add_module(str(idx)+ genericModule.__name__, genericModule())
def forward(self, X):
for m in self.children():
X = m(X)
return X
class Increment(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return (X + 1)
net = DaisyX(Increment, 5)
X = torch.zeros((2, 2))
net(X)

My exercise:
I don’t really understand this question, we use self.add_module method in nn.module to store modules (?), if we want to store modules in a Python list, meaning we have to rewrite the whole structure?
class parallelModule(nn.Module):
def init(self, net1, net2, dim):
super().init()
self.net1 = net1
self.net2 = net2
self.dim = dim
def forward(self, X):
output1 = self.net1(X)
output2 = self.net2(X)
return torch.cat((output1, output2), dim=self.dim)
My layer factory:
def layer_factory(num_layers):
layers =
for _ in range(num_layers):
layers.append(MLP())
return layers
My deep net work:
class DeepMLP(nn.Module):
def init(self, num_layers):
super().init()
layers = layer_factory(num_layers)
for idx, layer in enumerate(layers):
self.add_module(str(idx), layer)
def forward(self, X):
for module in self.children():
X = module(X)
return X

Hi, can I ask in your forward function return, why you need to wrap the concatenated (X, X2) inside a self.linear?
My function implementation just returns torch.cat((X, X2), dim=1)