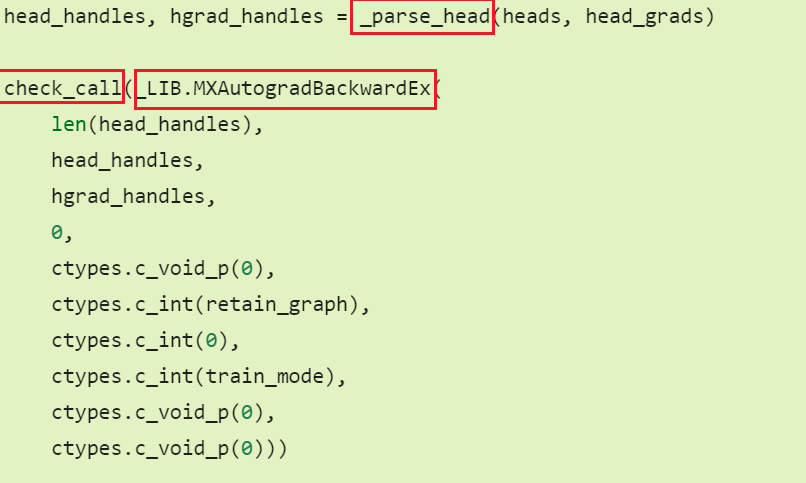
import numpy as np
from d2l import torch as d2l
x = np.linspace(- np.pi,np.pi,100)
x = torch.tensor(x, requires_grad=True)
y = torch.sin(x)
for i in range(100):
y[i].backward(retain_graph = True)
Why is the second derivative much more expensive to compute than the first derivative?
I know second derivatives could be useful to give extra information on critical points found using 1st derivative, but how does 2nd derivatives are expensive ?
Any specific reason not to use both torch and mxnet and how can we use the functions like attach_grad() and build a graph without using mxnet and only simple numpy ndarrays?
Oh yes, sorry, I initially used torch to use it’s sine function but couldn’t integrate with attach_grad and building the graph. Switched to numpy function but forgot to remove import torch
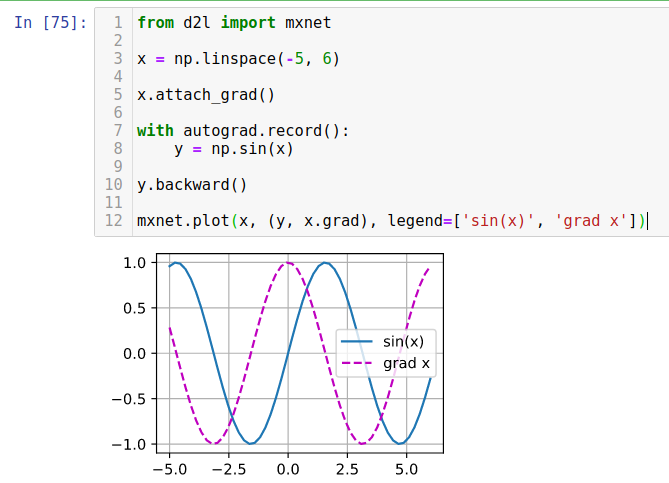
Plot sin(x) and derivative of sin(x) without the use of analytic form of the derivative can be achieved without the use of automatic differentiation framework provided by mxnet or pytorch, such as explained below :
I really dont understand Automatic Differentiation. Up until this topic, everything was intuitive and understanding for me. But i am kind of stuck here. Can i get a detailed explanation what Automatic DIfferentiation is used for. And the code is also not clear for me.
to automaticaly calculate the derivative of a function and
apply the resulted function to a given data.
E.g, suppose you use F(x) = 2sin(3x)* and you want to get the derivative of F for the value (array form) A=[1.,12.]
For doing so, you manually you calculate F’(x) = 6cos(3x) and then you apply value of A to the derivative, leading to [6cos(3), 6cos(36)]
Automatic differentiation avoid you to implement and calculate F’(A).
Just attaching the operator gradient to the x variable, with instruction x.attach_grad(), automatically triggers derivative operations as described just above :
the calculation of derivative F’(x) = 6cos(3x) and
the calculation of the value of A for this derivative : F’([1.,12.]) = [6cos(3), 6cos(36)]
This considerably ease the implementation of code with derivative operations, such as in back propagation.
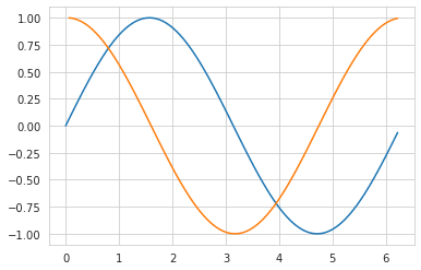
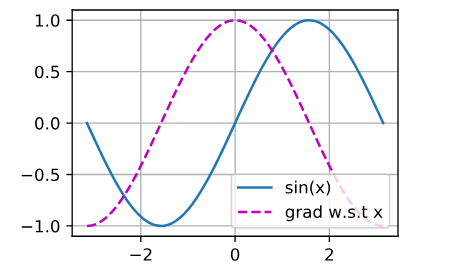
import math
import numpy as np
x = tf.range(-3,3,0.1)
y = np.sin(x)
d2l.plt.plot(x,y)
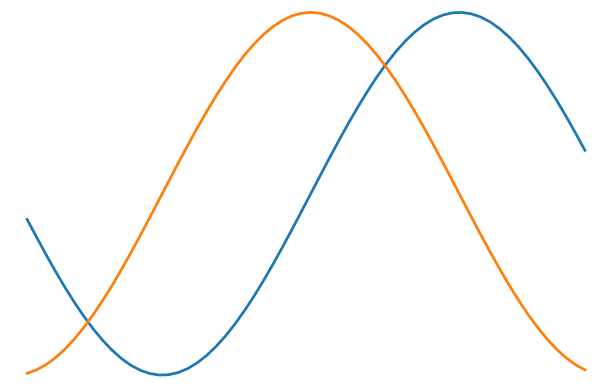
# gradient
with tf.GradientTape() as t:
t.watch(x)
p = tf.math.sin(x)
d2l.plt.plot(x,(t.gradient(p,x)))





 or a github URLto show code…
or a github URLto show code…