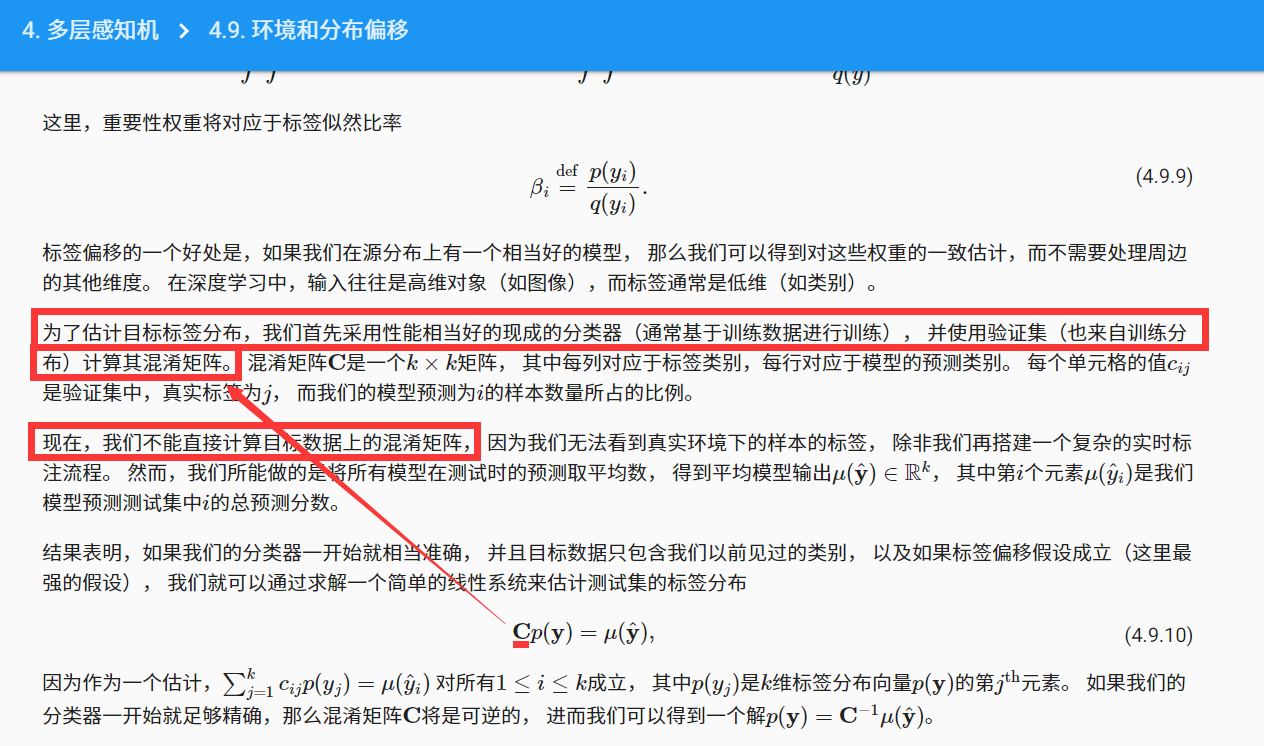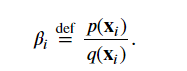
我觉得是这个公式决定的吧,要不然重要性权重就变成无穷大了


区分容易是因为无关因素有差异吗?不应该是无关因素差异越小越容易区分吗?另外抽样遇到协变量偏移是相对于什么而言的?是因为大学生的特征相对于一般健康男性发生了偏移吗?还是说用大学生作为健康样本训练出来的模型,用在测试所有其他病人时会遇到协变量偏移的情况。
2 replies
意思是说区分正负样本容易,因为正负样本在一些无关变量上差异很大。但是这些变量实际上和疾病预测无关,对预测疾病没有帮助。模型只是区分了年轻人和老年人而不是健康人和患者。

第二题是不是构建一个二分类,训练后得到的函数是h(x),若对于任意的x来源于训练集都有h(x)=0,那么就没有偏移,反之则发生了偏移

看下我和gpt的对话
Q: 也就是说,只有血液特征,没有年龄、激素水平、体力活动、饮食、饮酒等数据特征,训练出来的分类器可以很准确的区分病人和健康人,但是如果用来实际预测的化,效果很容易被干扰。
比如一个饮酒的健康人,可能血液样本会类似病人?
A:是的,您理解得非常正确。
在这个例子中,我们假设仅使用血液特征进行训练,并且没有考虑其他与疾病无关的因素。在这种情况下,分类器可能会在训练数据上表现出很高的准确度,能够很好地区分病人和健康人。
然而,在实际应用中,存在多种与疾病无关的因素,如年龄、激素水平、体力活动、饮食、饮酒等。这些因素可能会对血液样本产生影响,使得一些健康人的血液样本与患病人的血液样本相似,从而干扰了分类器的准确性。
比如,如果一个健康人长期饮酒,那么他的血液样本可能会反映出某种异常,类似于患病人的血液样本。这样,即使他是健康的,分类器也可能错误地将他归类为患病人。
因此,为了提高分类器的准确性和适用性,我们需要综合考虑多个因素,并引入更多相关的特征,而不仅仅依赖于血液特征。这样可以更好地对疾病进行预测和诊断,减少由于其他因素引起的误判。

第二题提示说构造一个分类器来实现协变量偏移检测器,常规思路可能就是用源分布来训练分类器,再在目标分布上进行测试,根据测试集上预测结果和实际标签的吻合情况来判断。可是这样怎么区分是协变量偏移还是分类器过拟合呢,还是说有更好的思路?还望各位大佬不吝赐教QwQ

感觉这一章节的内容翻译得很不好,语句都不通顺也缺乏逻辑,我怀疑是不是用机器翻译的


文中说了不能计算目标数据集的混淆矩阵C,计算的是源数据集的C,假设是一个很强的假设,( P(X|Y) ) 相同,说明了计算出来的比例是一样的,也就是C是一样的。直接说使用源的混淆矩阵也是可行的。
gpt4 回答的:
混淆矩阵 ( C ) 中的元素 ( C_{ij} ) 表示实际类别为 ( i ) 被预测为类别 ( j ) 的概率。因此,如果 ( P(X|Y) ) 上没有差异,那么预测错误的模式和错误概率在两个数据集之间应该是相似的。换句话说,混淆矩阵反映了特定标签下模型预测表现的内在属性,与标签的全局分布无关。

请问本章有英文版本吗?中文翻译版感觉有一些难以理解。



这一节基本都是迁移学习领域的内容,可以看看《迁移学习导论》详细了解一下

The overall of y hat, which is the mean of y hat in 4.9.10,
is the joint probability that the prediction = i and y actually is j.
The joint probability is the multiplication of condition probability P(y hat=i, y=j)
and event probability P(y=j).
So, Confusion matric “C” is that condition probability matrix.
C[i, j] represents prediction saying y hat = i in the condition y actually is j.

如果是向用户提供非同质化的内容,用户则会得到不一样的消息获得渠道,广告商会无法确定需要投递广告的目标用户从而浪费了投递成本。
带标签的测试数据集,输入到模型,计算损失,损失过大则发生了协偏移。
教材上所描述的方法,训练数据集和测试数据集同时打上标签,然后进行分类训练得到分类函数h,根据概率恒等式计算损失,也就是经验加权损失,优化损失,重新获得训练函数。
真实风险是指从训练数据集获得的标签错误风险,经验风险是根据训练经验对测试数据集打标签的风险。当发生分布偏移的时候,经验风险接近真实风险的程度会降低。
例如:模型拟合的程度越高,对真实风险的把控会更高,但对经验风险的把控降低,接近程度越低