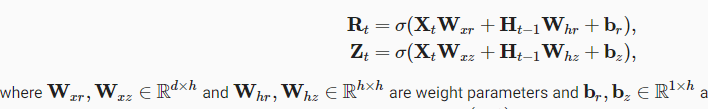Perhaps I’m missing something, but It looks like there’s a dimensionality disagreement:
Both products of X_tW_x and H_t-1W_h have shapes nxh, yet the biases have a shape 1xh.
Is there an implicit broadcasting being made for the bias terms to enable the summation?
1 reply
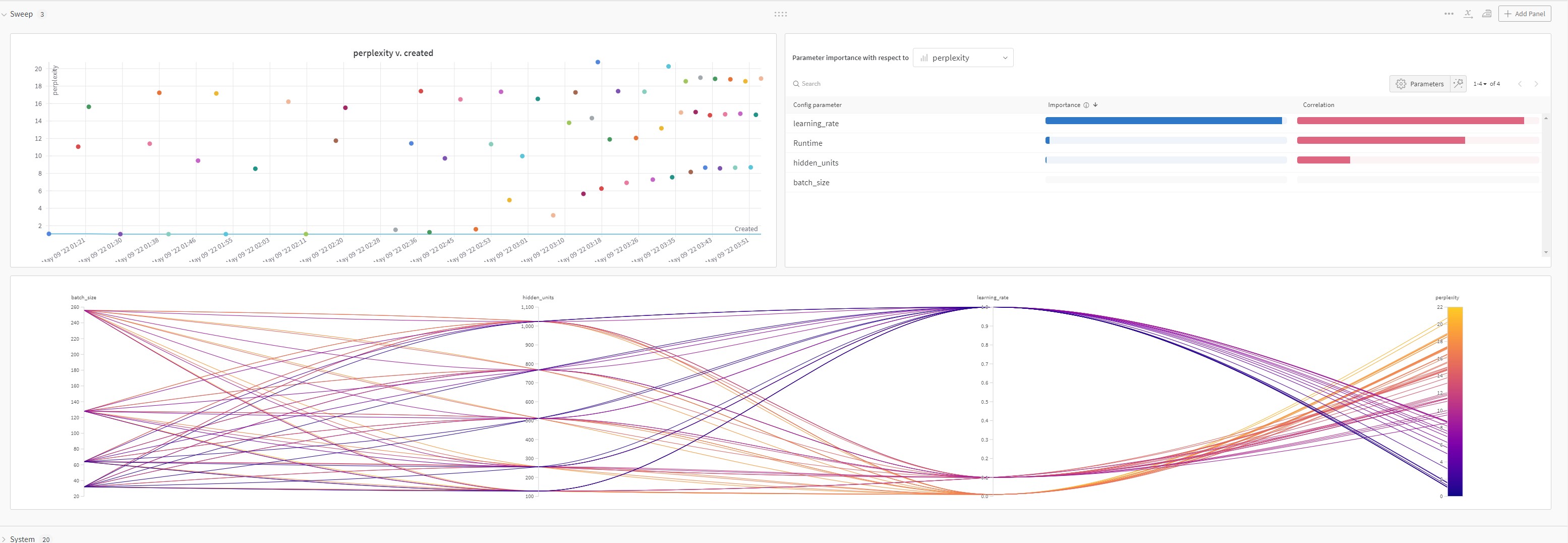
For optimizing the hyperparams on question 2, do we need to perform k-fold validation (and thus augment train_ch8), or just try out different hypers strait into the train_ch8 function itself?
I think in theory at least it would be correct to optimizer our hypers via the use of hold-out right?
since GRU has the power of mitigating gradients exploding, so why here still uses the old code block w/ grad clipping and detach()? how to reveal the value of GRU?